
3.4 정확한 trajectory만 있다면 reasoning 모델을 만들 수 있음.
-> 결과의 정확성보다 인지적 행동의 존재가 더 중요하다는 것을 시사
github : https://github.com/kanishkg/cognitive-behaviors
데이터 생성하는 방법도 참고해 볼 수 있음.
Abstract
- Test Time Compute으로 성능 향상을 이루었음(인지적 행동을 보임). 인지적 행동은 네가지로 나뉨.
- 검증(verification)
- 백트래킹(backtracking)
- 하위 목표 설정(subgoal setting)
- 역방향 연쇄(backward chaining)
- TTC는 강화학습으로 달성하나, 일부 모델은 잘 작동안함.
- Qwen은 추론 행동을 보이는 반면, Llama는 그렇지 아니함.
- 허나 적절한 추론 패턴을 포함한 데이터셋을 기폭재로 제공하면 Llama도 Qwen에 버금가게 개선이 가능하다는 것을 발견함.
1. Introduction
- 인간은 어려운 문제를 해결할 때 심사숙고함 -> RL로 훈련한 언어 모델도 유사한 추론 행동을 보임.
- 연구 목적: 언어 모델이 자기 개선을 하는 이유 및 핵심 인지적 행동에 초점을 맞추는 것을 목적으로 함.
- 연구 내용 :
- Qwen2.5-3B, Llama-3.2-3B Countdown에서 강화학습으로 훈련해 비교 분석함.
Qwen상당히 좋아짐 반면 Llama는 제한적인 성과를 보임. - 문제 해결에 유용한 인지적 행동을 분석하는 프레임워크 개발
- 검증, 백트래킹, 하위 목표 설정, 역방향 연쇄(backward chaining)
- Qwen2.5-3B, Llama-3.2-3B Countdown에서 강화학습으로 훈련해 비교 분석함.
- 실험 결과 :
- Llama 모델에 백트래킹을 포함한 합성 추론 궤적을 유도하여 강화학습 훈련 시 성능 개선 확인.
- 잘못된 해결책(틀린 답)으로 유도된 경우에도 적절한 추론 패턴을 보이면서 성능 개선이 지속됨을 확인.
- OpenWebMath에서 추론 행동을 강조하는 데이터를 선별하여 Llama 모델의 성능 개선 유도.

2. Related Work
추론을 강화하기 위한 방법으로 아래와 같은 연구들이 있었음.
- 외부 검색
- 추론 궤적 search, 병렬 샘플링, PRMS
-> 일반적으로 중복 탐색으로 효율성이 나쁨.
- 추론 궤적 search, 병렬 샘플링, PRMS
- In-Context Search and Self-Improvement
- ICL, finetuning on linearized search trace, training on self-correction examples
-> 자기 수정과 백트래킹처럼 원하는 행동을 취하기 위해 훈련 데이터를 잘 엔지니어링이 해야하는 경우가 많음.
- ICL, finetuning on linearized search trace, training on self-correction examples
- 강화학습
- On-policy, off-policy -> 추론 궤적에서 신용 할당(credit assignment)에 대한 접근 방식에 차이가 있음.
- R1에서 GRPO만으로도 추론 능력을 보임.
-> 그러나 왜 일부 모델은 RL을 통해 성공적으로 학습하는 반면 다른 모델은 개선에 실패하는지 답을 한 연구는 없음.
3. Method
3.1 Initial Investigation: A tale of two models
- 실험 설정 :
- 데이터: Countdown 게임을 테스트베드로 사용 (수학 퍼즐: 주어진 숫자와 연산으로 목표 숫자 만들기).
- 모델 : Qwen-2.5-3B, Llama-3.2-3B
- Object : PPO -> 더 안정적이라 선택 (GROP, REINFORCE로 해도 비슷한 결과)
- PPO 알고리즘으로 250단계 훈련 (프롬프트당 4개의 trajectory 샘플링).
- 구현 : VERL 라이브러리 및 TinyZero 구현을 활용하여 강화 학습 실험 수행.
- 결과:
- Qwen은 30단계 이후 급격한 성능 향상보임, 반면 Llama는 성능향상 미비(Figure1)
- Qwen은 훈련 후반에 명시적 검증에서 암묵적 해결책 확인으로 전환하는 행동 변화를 보임
명시적 검증 예) 8*35는 280이고 너무 높습니다.
암묵적 해결 예) 단어를 사용하지 않고 올바른 답을 찾을 때까지 순차적으로 다른 해결책을 시도함
- Question :
- 성공적인 추론 기반 개선을 가능하게 하는 기본적인 능력은 무엇인가?
- 인지적 행동을 분석하기 위한 체계적인 프레임워크가 필요하다.
3.2 A Framework for Analyzing Cognitive Behaviors
- 먼저 인지적 행동을 정의함 : 정의함으로서 모델 출력에서 인지적 행동을 식별할 수 있음.
- 4가지
- 백트랙킹 : 오류 감지 시 풀이 과정을 명시적으로 수정함
- 검증 : 중간 결과 확인
- 하위 목표 설정 : 복잡한 문제를 여러 단계로 분할
- 역방향 chain: 결과에서 입력으로 역으로 추적함 (75에 도달하기 위해, 나눌 수 있는 숫자 필요)
- GPT-4o-mini를 사용해 모델 출력에서 이러한 패턴을 식별하는 파이프라인 개발
- 4가지
3.3 The Role of Initial Behaviors in Self-Improvement

- Qwen의 성능 향상은 검증 및 백트래킹을 중심으로 발현됨. (그림1의 중간 밑 부분)
- 반면 Llama는 없었음.
- 훈련 전 모델로 비교
- Qwen-2.5-3B: 네 가지 행동 모두 비율이 Llama 변형보다 높음 (그림 4).
- Llama-3.1-70B: Llama-3.2-3B보다 행동 활성화 증가, 하지만 불균등 (특히 백트래킹은 제한적).
3.4 Intervening on initial behaviors
인지적인 행동이 중요한 것은 알았음. 근데 그러면 인지적 행동이 발생하지 않는 모델을 어떻게 하면 행동이 발생할 수 있게 하나?
- 데이터셋 준비 : Cluade-3.5-Sonnet으로 CountDown문제 추론 과정 생성
- 모든 전략 결합(검증, 백트래킹, 하위 목표 설정, 역방향 연쇄 모두 포함)
- 백트래킹만 포함
- 백트래킹 + 검증 포함
- 백트래킹 + 하위 목표 설정 포함
- 백트래킹 + 역방향 연쇄 포함
- 빈 chain of thought(아무 인지적 행동 없음)
- 길이가 일치하는 의미 없는 토큰으로 채워진 chain-of-thought
- 추가 실험
- 인지적 행동 패턴을 보이는 데이터를 만들지만, 정답이 틀린 데이터셋도 생성
-> 행동 패턴과, 정확성 중 어느 것이 더 중요한것인지 확인하기 위해서
- 인지적 행동 패턴을 보이는 데이터를 만들지만, 정답이 틀린 데이터셋도 생성
- 실험 과정
- 파인튜닝 : 각 데이터셋으로 각 모델을 파인튜닝(SFT - Appendix B.Priming)
- 강화학습 : 파인튜닝 모델들을 PPO 알고리즘을 적용해, CountDown문제 해결 능력 향상시킴.
- 결과 :
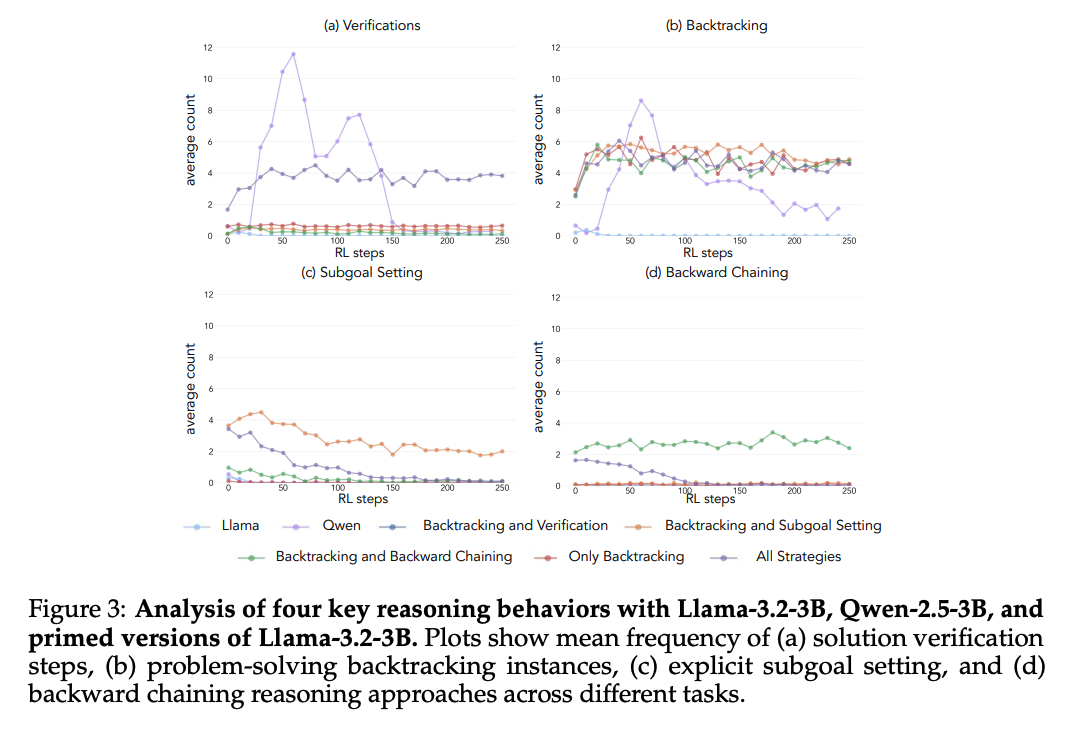
- Priming with different behaviors: Llama, Qwen파인튜닝후 RL하면 상당한 개선을 보임(Figure 2). 프라이밍을 하게 되면 유용한 행동을 증폭하고, 다른 행동을 억제하는 것을 보임(Figure 3).
-> 모든 전략 결합한 데이터에서는 백트래킹과 검증은 유지하고 강화하는 반면 역방향 연쇄와 하위 목표 설정은 훈련이 진행될 수록 감소. 억제된 행동(역방향 연쇄와 하위 목표 설정)은 백트래킹과만 짝을 이루었을 때 훈련 전반에 걸쳐 지속
- Priming with different behaviors: Llama, Qwen파인튜닝후 RL하면 상당한 개선을 보임(Figure 2). 프라이밍을 하게 되면 유용한 행동을 증폭하고, 다른 행동을 억제하는 것을 보임(Figure 3).

- Testing Behavioral Necessity: empty CoT로 SFT후 훈련 후 결과는 그림5와 같은데, 모델 성능은 Llma기준 30~35%임.
-> 인지적 행동 없이 추가 토큰을 할당하는 것만으로는 테스트 시간 계산을 효과적으로 사용할 수 없다는 것을 보여줌

- Behaviors versus Correctness: 올바른 행동이지만 정답이 틀린 모델로 훈련된 모델과, 정확한 해결책이 있는 데이터셋으로 훈련된 모델과 동일한 성능을 달성함(그림 6).
-> 인지적 행동의 존재가 강화 학습을 통한 성공적인 자기 개선을 가능하게 하는 중요한 요소라는 것을 시사함.
(손상된 추론 궤적에서 학습하는 것을 보여주는 이전 연구(Li et al., 2025)를 확장)
-> 결과의 정확성보다 인지적 행동의 존재가 더 중요하다는 것을 시사
