3.3부분 - Custom Long CoT
4.2 궁금한 것은, figure4에서보면 길이가 증가하지 않은것처럼 보임. 근데 성능은 올라감. iteration을 계속 진행할 경우, model이 갖고 있는 Inteligence한계에 봉착할 것으로 생각되는데, 과연 그때가서 length를 늘릴 것인가? length가 늘어나는게 TTC의 핵심중 하나인데, 어떻게 행동할지가 궁금함.
4.4 일반적으로 context가 길어질수록 성능이 좋은 것은 밝혀짐. 따라서 여기 저자들은 모델이 더 큰 컨텍스트 윈도우 크기를 완전히 활용하기 위해 더 많은 학습 샘플이 필요할 수 있다고 생각한 것으로 보임.
5.1 QwQ로 데이터를 생성할 때, Instruct:Answer -> refine instruct, refine answer를 생성한것인지, 혹은 Instruct만 입력으로 QwQ에 넣어 생성한 답변으로 데이터를 생성한 것인지...
Abstract
Scaling inference compute LLM의 추론 능력을 향상시킴, Long CoT는 역추적 및 오류 수정과 같은 전략을 구사함.
이 연구에서는 Long CoT 추론의 작동 방식을 체계적으로 탐구하여, 모델이 긴 CoT 궤적을 생성하도록 하는 주요 요인들을 찾고자 함.
SFT 및 RL 실험을 통해 네 가지 주요 연구 결과를 도출
- (1) SFT가 반드시 필수적인 것은 아니지만, 학습 과정을 간소화 효율화 함
- (2) 추론 능력은 학습 연산량이 증가함에 따라 발현되는 경향을 보이지만, 항상 보장되는 것은 아님.
- (3) RL에서는 검증 가능한 보상 신호를 확장하는 것이 핵심
- (4) 오류 수정과 같은 핵심 능력은 기본 모델에 이미 내재되어 있지만, RL을 통해 복잡한 과제에서 이러한 능력을 효과적으로 발휘하도록 장려하기 위해서는 상당한 연산 자원이 요구됨.
1. Introduction
- LLM에서 추론 능력을 활성화하는 핵심 기술은 chain-of-thought(CoT) 프롬프팅임.
- LLM은 CoT를 사용하더라도 복잡한 문제(수학 경시대회,PhD 수준, 소프트웨어 엔지니어링)풀지 못함.
- 최근 OpenAI의 o1은 어려운 문제를 풀었음. 이 모델의 핵심 특징은 긴 CoT로 추론 계산을 확장하여, 실수 인식 및 수정, 어려운 단계 분해, 대안적 접근법 반복과 같은 전략을 사용
- 여러 노력들이 긴 CoT를 생성하도록 LLM을 훈련시켜 o1 모델의 성능을 복제하려고 시도함.
- 정답 기반(정확성) 검증 가능한 보상에 의존. 강화학습의 보상 해킹을 방지
- 그러나 모델이 어떻게 긴 CoT를 학습하고 생성하는지에 대한 이해는 없음.
- 이 연구에서는 긴 CoT 생성의 기본 메커니즘을 체계적으로 조사한다.
- 긴 CoT를 위한 SFT - 긴 CoT 추론을 가능하게 하는 가장 직접적인 방법. 긴 CoT SFT가 모델이 더 높은 성능에 도달하도록 하고, 짧은 CoT보다 RL 개선을 더 쉽게 할 수 있게 함을 발견
- Challenges in RL-driven CoT scaling - RL이 항상 안정적으로 CoT 길이와 복잡성을 확장하지는 않는다는 것을 관찰했다.
- 이를 해결하기 위해, 분기와 백트래킹과 같은 추론 행동을 장려하면서 CoT 성장을 안정화하는 반복 패널티가 있는 코사인 길이 스케일링 보상을 도입
- Scaling up verifiable signals for long CoT RL - 검증 가능한 보상 신호는 긴 CoT RL을 안정화하는 데 필수적임. 그러나 고품질의 검증 가능한 데이터는 많이 없다.
- 노이즈가 있는 웹 추출 솔루션을 포함하는 데이터 사용을 탐색한다. 이러한 "실버" supervission signal가 불확실성을 유발하나, 분포 외(OOD) 추론 시나리오에서 특히 유망함을 발견
- Origins of Long CoT Abilities and RL Challenges - 말하고자 하는 바를 모르겟음.
2. Problem Formulation

2.1 Notation
- 쿼리:
- 출력 시퀀스:
- $π_{\theta}$ : LLM
- $π_{\theta}(y_t | x, y_{1:t-1})$ : 출력 토큰에 대한 조건부 분포
- 생성된 출력에서 chain-of-thought를 구성하는 토큰을 나타냄. 최종 답변은 y의 마지막 부분일 수 있음.
- '긴 chain-of-thought(긴 CoT)'라는 용어를 사용하여 평소보다 더 긴 길이를 보여주며 다음과 같은 행동들이 있음.
- 분기와 백트래킹: 모델이 체계적으로 여러 경로를 탐색하고(분기) 특정 경로가 잘못된 것으로 판명되면 이전 지점으로 되돌아감(백트래킹).
- 오류 검증 및 수정: 모델이 중간 단계에서 불일치나 실수를 감지하고 일관성과 정확성을 복원하기 위한 수정 조치를 취함
2.2 SFT
Policy(LLM)을 SFT를 통해 초기화함. 이때 사용하는 데이터는 $D_SFT = {(x_i,y_i)^N_{i=1}}$, 여기서 $y_i$는 일반적인 CoT이거나 long CoT임.
2.3 RL
SFT 뒤, 강화학습으로 긴 CoT 생성을 더 최적화할 수 있음.
- 보상 함수: 정확하고 검증 가능한 추론을 장려하도록 설계된 스칼라 보상 $r_t$ 정의. 최종 답변에 대해 생성된 결과 기반 보상 고려. 최종 솔루션의 정확성을 포착하는 용어를 $r_{answer}(y)$로 표시
- 정책 업데이트: PPO 채택. 정답과 직접 비교하는 규칙 기반 검증을 보상 함수로 사용.
2.4 Training Setup
- Base Model : Llama-3.1-8B, Qwen2.5-7B-Math
- Data : MATH 7500데이터
- SFT에서 정답이 있는 데이터는 rejection sampling을 통해 응답을 합성함.
- 프롬프트당 고정된 수의 후보 응답을 생성하고, 정답과 일치하는 응답만을 남김.
2.5. Evaluation Setup
- MATH-500, AIME2025, TheoremQA, MMLU-Pro-1k
3 Impact of SFT on Long CoT
SFT를 위한 긴 CoT와 짧은 CoT 데이터를 비교, RL의 시작점으로서도 비교
3.1 SFT Scaling
첫 번째 단계 : CoT 데이터에 base 모델을 sft. 짧은 CoT는 일반적이므로 이에 대한 SFT 데이터를 모으는 것은 간단. 그러나 고품질 긴 CoT 데이터를 얻는 방법은?????????.
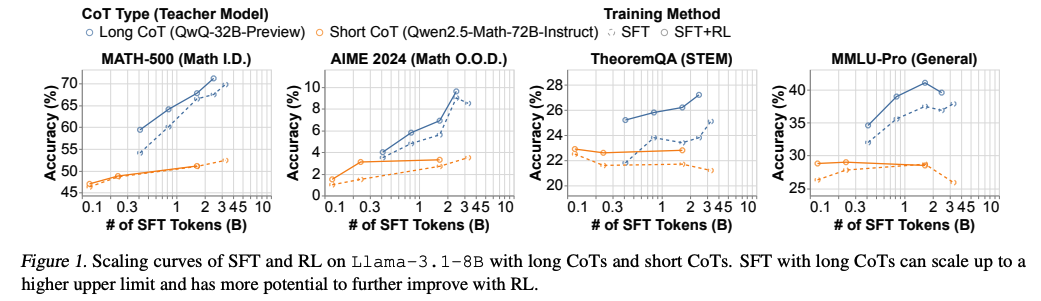
- Setup :
- 긴 CoT : QwQ-32B-Preview에서 데이터 생성
- 짧 CoT : Qwen2.5-Math-72B-Instruct에서 생성
- N개 생성하고, 정답과 일치하는 응답만 필터링.
- Result : Short CoT(주황) 성능이 금방 Converge함.
-> 긴 CoT가 있는 SFT는 짧은 CoT보다 더 높은 성능 상한선까지 확장될 수 있다
3.2 SFT Initialization for RL
Result : 위 마지막 그림을 보면, SFT, SFT+RL을 비교함. SFT+RL이 더 높은 성능을 보임. -> DeepSeekR1에서도 언급했었음.
3.3 Sources of Long CoT SFT Data
- (1) 짧은 CoT 모델을 프롬프팅하여 원시 액션을 생성하고 순차적으로 결합하여 긴 CoT 궤적을 구성(Construct)
- 긴 CoT 궤적을 구성하기 위해, 원시 액션을 정의.
- clarify, decompose, solution_step, reflection, answer.
- Qwen2.5-72B-instruct로 다단계 프롬프팅을 사용해 이러한 액션을 순차적으로 배치했으며, o1-mini로 reflection, self-correction부분을 수행.
- 긴 CoT 궤적을 구성하기 위해, 원시 액션을 정의.
- (2) Reaoning모델에서 증류.
- QwQ-32B-Preview에서 생성된 데이터로 학습
- 둘다 모두 Reject sampling사용. Llma-3.1-8B로 훈련. 200k SFT 유지
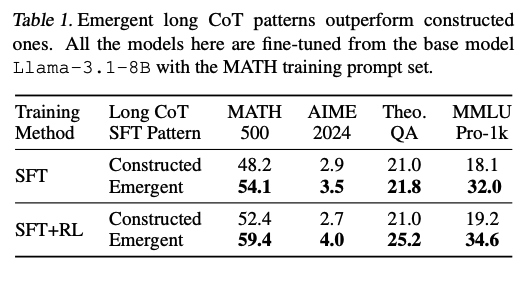
- (2)증류된 모델이 더 잘 일반화되고, RL로 더 크게 개선될 수 있는 반면, (1)패턴으로 학습된 모델은 그렇지 않다는 것을 보여줌.
- 대부분의 실험을 증류된 긴 CoT 궤적을 기반으로 수행하는 이유이기도 함.




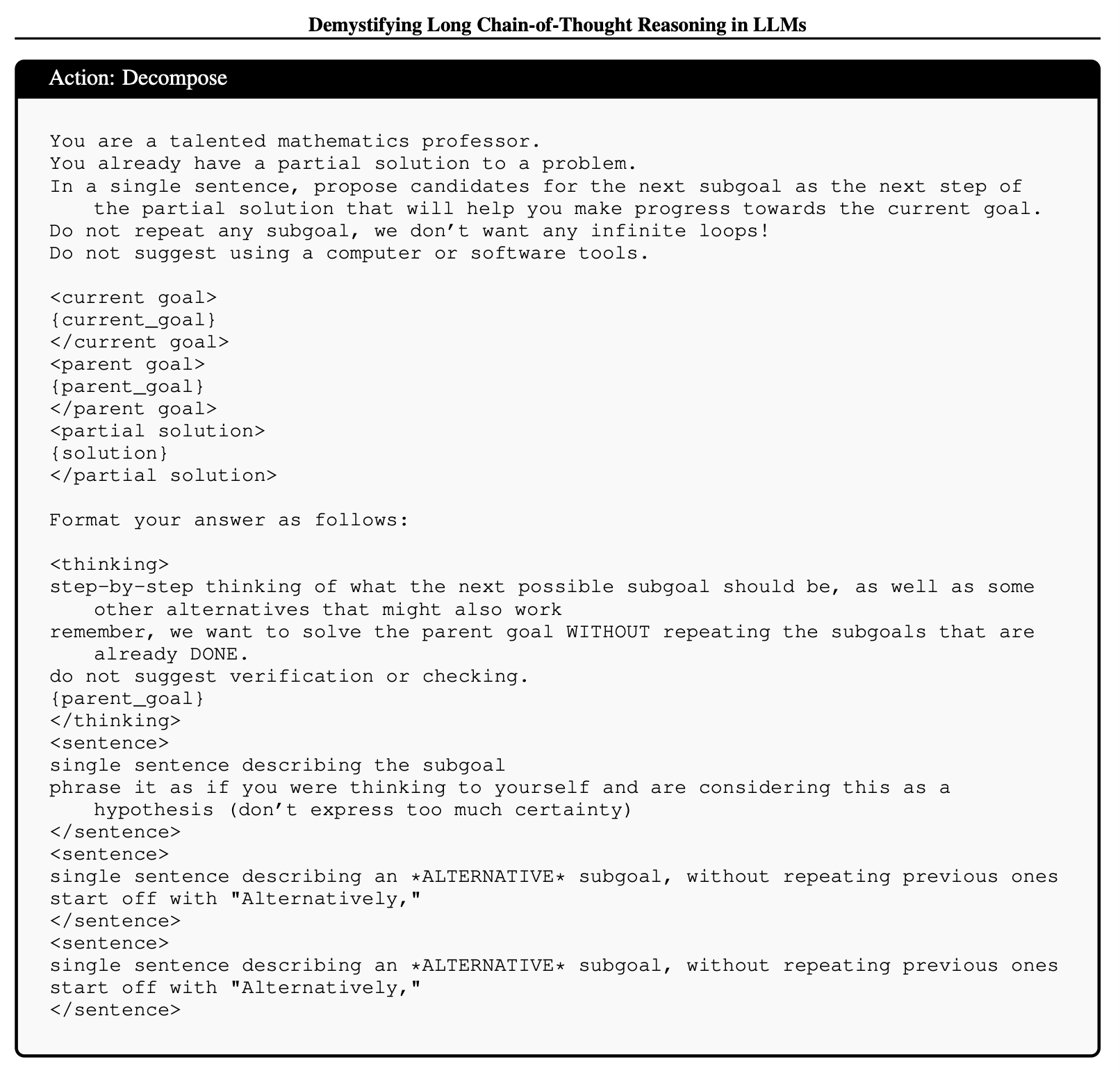

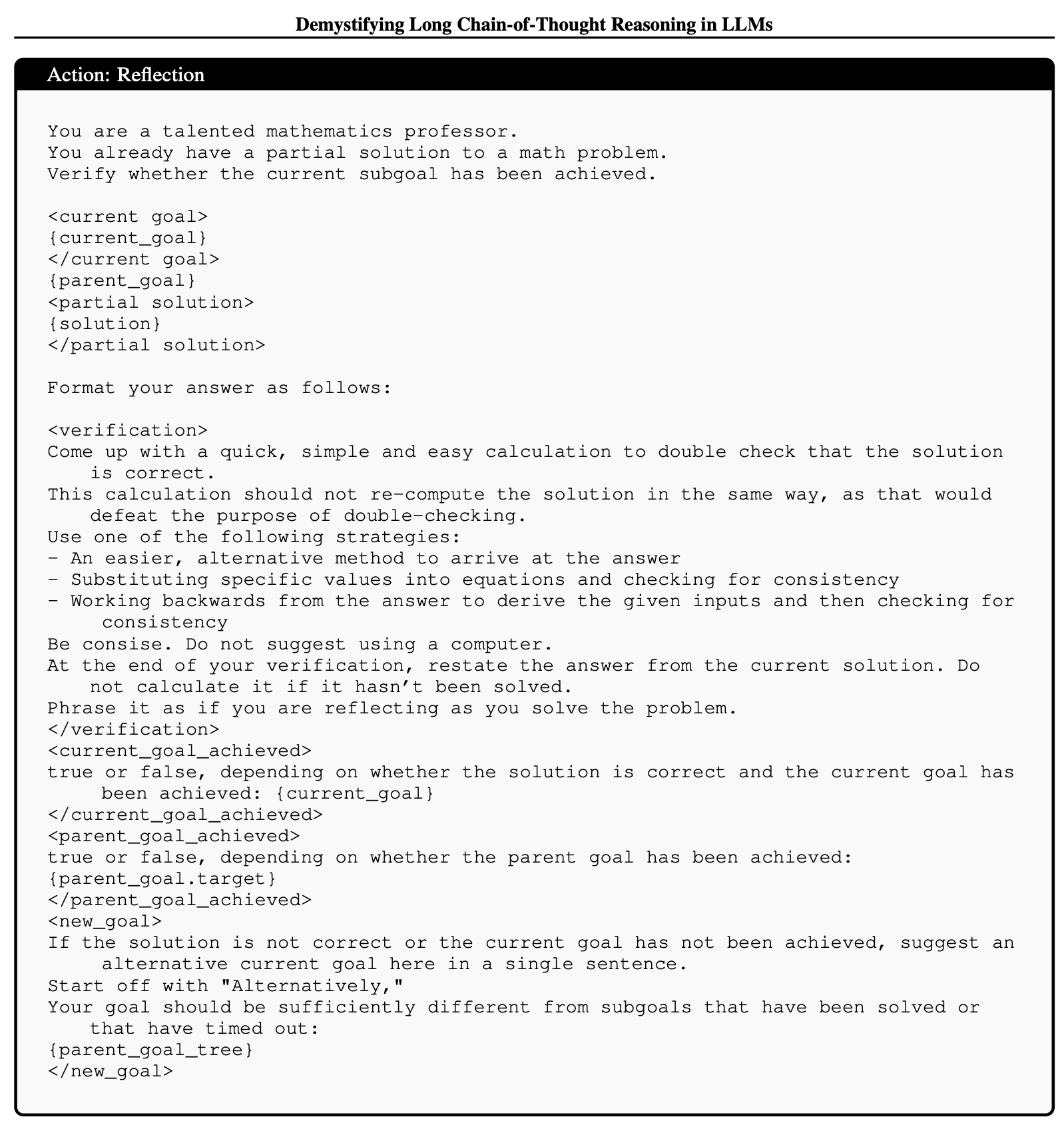

4. Impact of Reward Design on Long CoT
보상 함수 설계에 대해 살펴봄.
4.1. CoT Length Stability
최근 긴 CoT에 관한 연구들은 모델이 사고 시간을 늘릴수록 추론을 잘한다 한다. 이 연구의 실험은 QwQ-32B-Preview에서 증류된 긴 CoT로 SFT된 모델이 RL 학습 중에 CoT 길이를 확장하는 경향이 있음을 확인했지만, 때로는 불안정하게 나타남. 이 불안정성은 Kimi Team(2025)과 Hou et al.(2025)에 의해서도 발견되었고, 학습 안정화를 위해 길이 및 반복 패널티를 기반으로 한 기법을 사용했다.
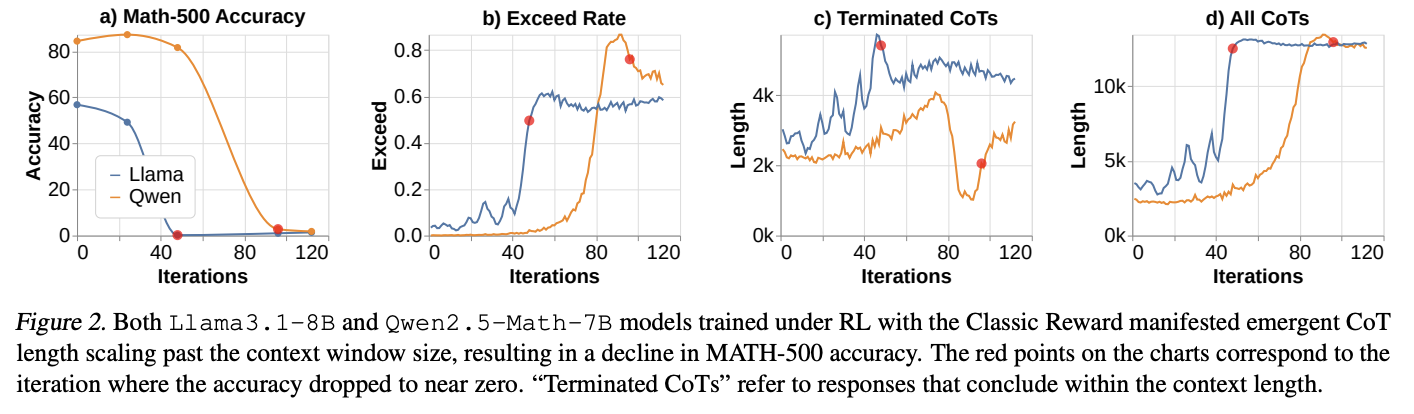
- Llama3.1-8B와 Qwen2.5-Math-7B을 사용한 실험에서, RL로 학습 중 CoT 길이가 증가하여 결국 윈도우 제한에 도달함.
- 이로 인해 컨텍스트 윈도우 크기를 초과하는 CoT가 생성되면서 학습 정확도가 감소함.(그림2)
- 모델별로 서로 다른 동작을 보임. 상대적으로 성능이 안좋은 Llama-3.1-8B 모델은 Qwen-2.5-Math-7B보다 CoT 길이의 변동이 더 크게 나타남
- 그림2 b를 보면, 컨텍스트 윈도우 크기를 초과하는 CoT의 비율이 60%에서 안정화되는 것처럼 보임.
이말은 -> 컨텍스트 윈도우 크기가 implicit하게 컨텍스트 길이 제한 역할을 한다는 점이다.- 명시적으로 컨텍스트 길이를 길게 만들면 페널티를 주는것이 없더라도, 강화학습에서는 알아서 판단함. 마치 명시적으로 벽이 안보이더라도 학습 과정에서 모델이 보이지 않는 벽을 인식하게 되는 것과 같다. 공식적으로 여기까지만 가라고 말하지 않았지만, 그 이상으로 가는 샘플들이 자연스럽게 성능이 안좋으니, 모델이 스스로 경계를 인식한다.
4.2 Active Scaling of CoT Length
- reward shaping을 통해 length 스케일링을 안정화할 수 있다는 것을 발견
- 첫째, 정확한 CoT는 잘못된 CoT보다 높은 보상을 받음
- 둘째, 더 짧은 정확한 CoT는 더 긴 정확한 CoT보다 높은 보상을 받음.(skythought-flash와 비슷함)
- 셋째, 더 짧은 잘못된 CoT는 더 긴 잘못된 CoT보다 더 높은 페널티를 받는다.
-> 이는 정답을 얻을 가능성이 낮은 경우 모델이 사고 시간을 연장하도록 한다.
- 위 조건을 만족하는 '코사인 보상'을 제안. CoT 끝에서 정답의 정확성에 따라 한 번만 주어지는 sparse 보상이다.
사실 이 함수는 그래디언트 디센트 최적화에서 학습률 조절할 때 사용됬었음.(figure3)
논문에는 안나와있어서 찾아봄. $CosFn(t,T,min,max) = min + \frac{1}{2}(max-min)(1+cos(\frac{t\pi}{T}))$
- 실험 결과, 코사인 보상이 RL 하에서 모델의 길이 스케일링을 크게 안정화시키고, 학습 정확도를 안정화시키며, RL 효율성을 개선하는 것으로 나타남. 또한 다운스트림에서도 모델 성능이 향상되었음.



- Setup : 클래식 보상과, 코사인 보상을 비교함.
- 결과 : 코사인 보상은, length scaling을 안정화시켰음. 따라서 RL 효율성이 향상되었음(Figure4). 또한, 성능도 개선되었음(Figure5).
- 코사인 보상을 사용한 Llama3.1-8B 모델은 훨씬 더 안정적인 (a) 학습 정확도와 (b) 응답 길이를 보여주었다.
- 안정성은 다운스트림 작업에서의 성능 향상으로 이어짐.
- 궁금한 것은, figure4에서보면 길이가 증가하지 않은것처럼 보임. 근데 성능은 올라감. iteration을 계속 진행할 경우, model이 갖고 있는 Inteligence한계에 봉착할 것으로 생각되는데, 과연 그때가서 length를 늘릴 것인가? length가 늘어나는게 TTC의 핵심중 하나인데, 어떻게 행동할지가 궁금함.
4.3 Cosine Reward Hyperparameters
코사인 보상 하이퍼파라미터는 다양한 방식으로 CoT 길이를 형성하도록 조정함.

- 실험 : 다양한 하이퍼파라미터 실험.
- 모델 - Llama3.1-8B(QwQ-32B-Preview에서 긴 CoT로 증류된 데이터로 파인튜닝)
- 다양한 하이퍼파라미터 실험 : $r^c_0, r^c_L, r^w_0, r^w_L$
- 결과 :
- 정확한 답변에 대한 보상이 CoT 길이에 따라 증가하면($r^c_0 < r^c_L$) CoT 길이가 폭발적으로 증가하는 것을 발견함.
- 정확한 보상 < 잘못된 보상에 비해 낮을수록 CoT 길이가 길어짐. - 위험 회피.
4.4 Context Window Size
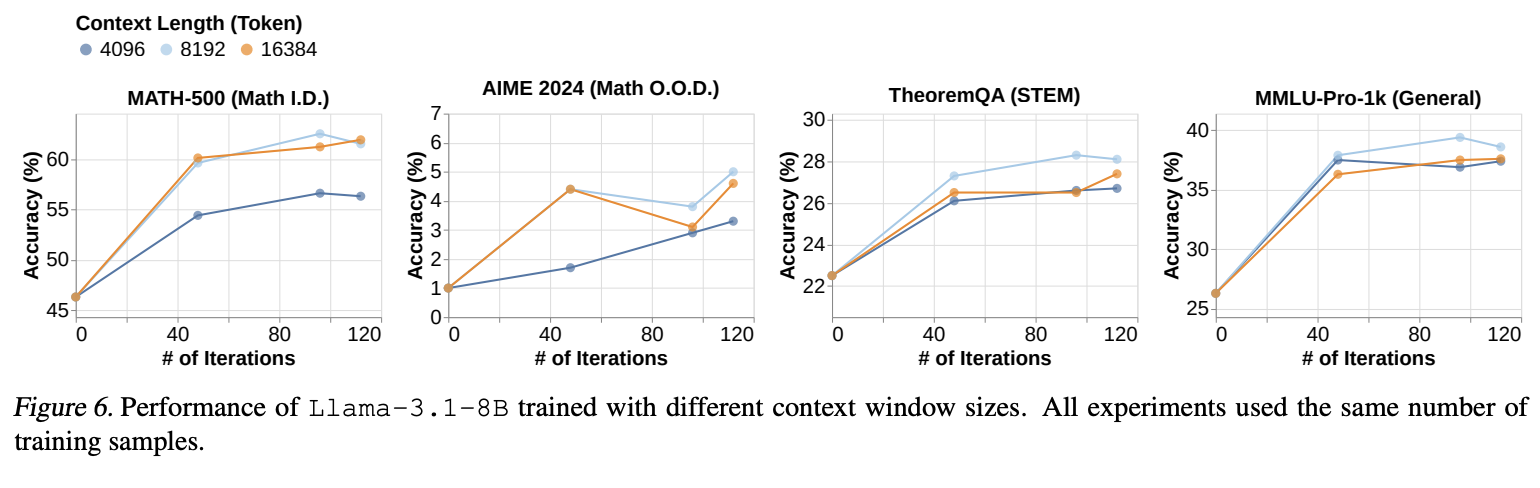
- 더 긴 컨텍스트는 -> 모델에게 더 많은 탐색 공간을 제공하며, 더 많은 학습 샘플을 모아 많은 부분을 활용하는 법을 배운다.
- 그럼??? : 더 큰 컨텍스트 윈도우를 활용하기 위해 더 많은 학습 샘플이 필요한가?
- 실험 :
- 모델 : QwQ로 증류되어 학습된 모델
- 데이터 : MATH
- 학습 : RL(cosine)
- 실험 : window size 4k, 8k 16k
- 결과 : Figure6 - 8k에서 가장 성능이 좋았음.
- 일반적으로 context가 길어질수록 성능이 좋은 것은 밝혀짐. 따라서 여기 저자들은 모델이 더 큰 컨텍스트 윈도우 크기를 완전히 활용하기 위해 더 많은 학습 샘플이 필요할 수 있다고 생각한 것으로 보임.
4.5 Length Reward Hacking
- 문제점 :
- 보상을 많이 받기 위해, 모델은 어려운 문제에 부딛치면, 비슷한 말을 반복함.
- 모델 분기가 감소함(alternatively 단어 카운팅)
- 해결 :
- N-gram 페널티 알고리즘 구현.
- 미해결 : 허나, 학습 정확도가 낮을 때 보상이 CoT길이에 더 큰 상향 압력을 가해 반복을 통한 보상 해킹을 증가시킴. 더 강력한 반복 패널티가 필요한데, 추후 연구로 남김.
4.6 Optimal Discount Factors (생략)
5. Scaling up Verifiable Reward
검증 가능한 보상 신호(정답, 정확도 등)는 긴 Chain-of-Thought(CoT) 강화학습(RL)을 안정화하는 데 필수적이다. 허나 이러한 데이터는 한정적임. 이를 해결하기 위해, 웹 코퍼스에서 추출한 추론 관련 질문-답변 쌍과 같이 노이즈가 있더라도 더 쉽게 구할 수 있는 다른 데이터를 사용하는 방법을 탐구. 구체적으로, WebInstruct 데이터셋을 실험하며, 효율성을 위해 MinHash를 통해 중복 제거한 WebInstruct-462k 서브셋을 구성.
5.1 SFT with Noisy Verificable Data
SFT에 다양한 데이터를 추가하는 방법을 탐색. 신뢰할 수 없는 데이터가 있더라도 다양한 데이터는 RL중 모델의 탐색을 촉진할 수 있음.
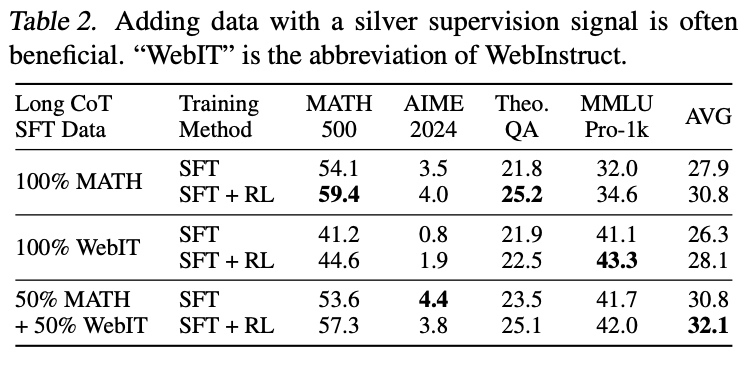
- Setup :
- 데이터 : golden 답이 있는 비율을 0, 50, 100%로 비교 실험
- 데이터 생성 : QwQ에서 긴 CoT 생성.
- Golden : Math와 같은 것은 rejection sampling을 통해서 거름.
- WebInstruct : Teacher모델에서 1개 대답을 생성함.
-> ??????? 답이 맞는지 안맞는지 정도는 sampling해야 하는것 아닌가??????????????
-> WebInstruct데이터셋을 만든 논문을 찾아보니, 답변의 중간 과정들을 매꿔주는 작업을 하였다고 함.
- 훈련 : 3.2에서 언급한 RL을 사용함.
- BaseModel : Llama-3.1-8B
- 의문점 :
- QwQ로 데이터를 생성할 때, Instruct:Answer -> refine instruct, refine answer를 생성한것인지, 혹은 Instruct만 입력으로 QwQ에 넣어 생성한 답변으로 데이터를 생성한 것인지...
- 결과 : 위 테이블 - 일반적인 reasoning능력을 평가하는 MMLU Pro-1k와 같은 부분에서, 매우 높은 개선이 있음.
5.2 Scaling up RL with Noisy Verification Data
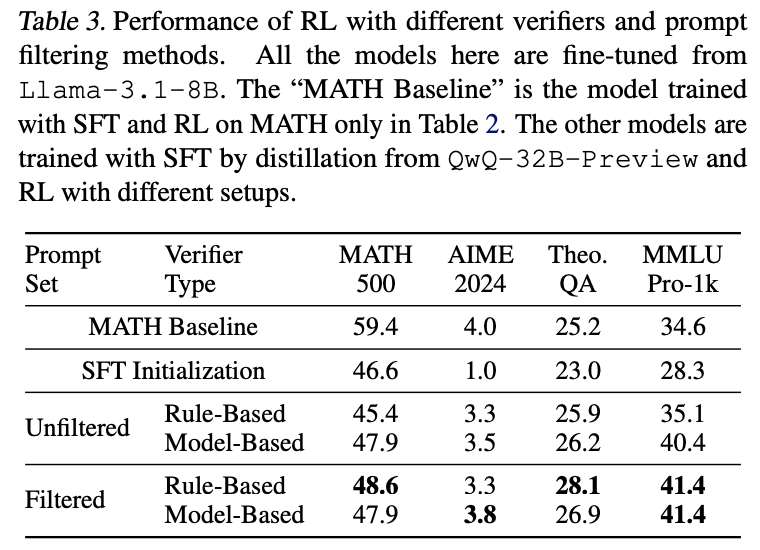
- 실험 순서
- 1. 짧은 답변 추출

- 2. 품질 검증을 위한 Rejection Sampling
- 위에서 샘플링한 데이터에, QwQ-32B-Preview를 사용해 각 데이터에 대해 2개 응답을 생성. 답이 일치하지 않는 답은 버림
- 결과 : 462K 데이터에서 115K만 남음.
- WebInstruct문제는 짧은 형태 답변으로 변환하기 어려움.
- 일부 프롬프트는 QwQ-32B-Preview에게도 어려워, 정확한 답변 생성 불가능.
- 3. Verifier구현
- Rule Based Verifier : 모델 출력과 정답과 비교, 짧은 형태의 답변만 효과적으로 처리 가능
- Model-based verifier : Qwen2.5-Math-Instruct모델에 다음 프롬프트 제공 :

- 4. SFT수행 : 필터링된 115K데이터를 Llama3.1-8B에 훈련
- 5. RL 실험
- 1. 필터링 되지 않은 데이터 + 규칙 기반 verifier :
- 462K 데이터 셋 사용, 규칙 기반 verifier로 보상 생성
- 2. 필터링 되지 않은 데이터 + 모델 기반 verifier :
- 462K, 모델 기반 verifier로 보상 생성.
- 3. 필터링 데이터 + 규칙 기반 : 115k, 규칙 기반
- 4. 필터링 데이터 + 모델 기반 : 115k, 모델 기반
- 1. 필터링 되지 않은 데이터 + 규칙 기반 verifier :
- 6. RL 훈련 : 각 실험에서 30K 데이터 추출, 각 프롬프트당 4개 응답 생성, PPO로 실험 진행
- 7. 결과 : 짧은 형태 답변으로 필터링한 데이터 + 규칙 기반 검증 조합이 가장 좋은 성능을 달성함. 이는 적절한 필터링 후 규칙기반 검증이 더 정확한 보상 신호를 제공할 수 있음을 시사함.
- 고품질 보상 신호 데이터가 중요함
6. Exploration on RL from the Base Model
7. Discussion and Future Work