
0. Abstract
test time scaling은 매우 좋은 성능을 보이나, o1의 성능을 복제하는데는 실패함. 이 연구는 좋은 추론 성능을 달성하기 위한 방법을 찾고자 한다.
- 난이도, 다양성, 품질 세 가지 기준으로 작은 데이터셋 (추론 과정이 포함된 1,000개의 질문 쌍)를 구성
- 모델의 사고 과정을 강제로 종료하거나, 모델이 종료하려고 할 때 Wait를 여러 번 추가하여 모델의 생성을 연장하여 테스트 타임 계산을 제어하는 budget forcing을 개발. 이로 인해 모델이 자신의 답을 다시 확인하게 되어, 종종 잘못된 추론 단계를 수정함.
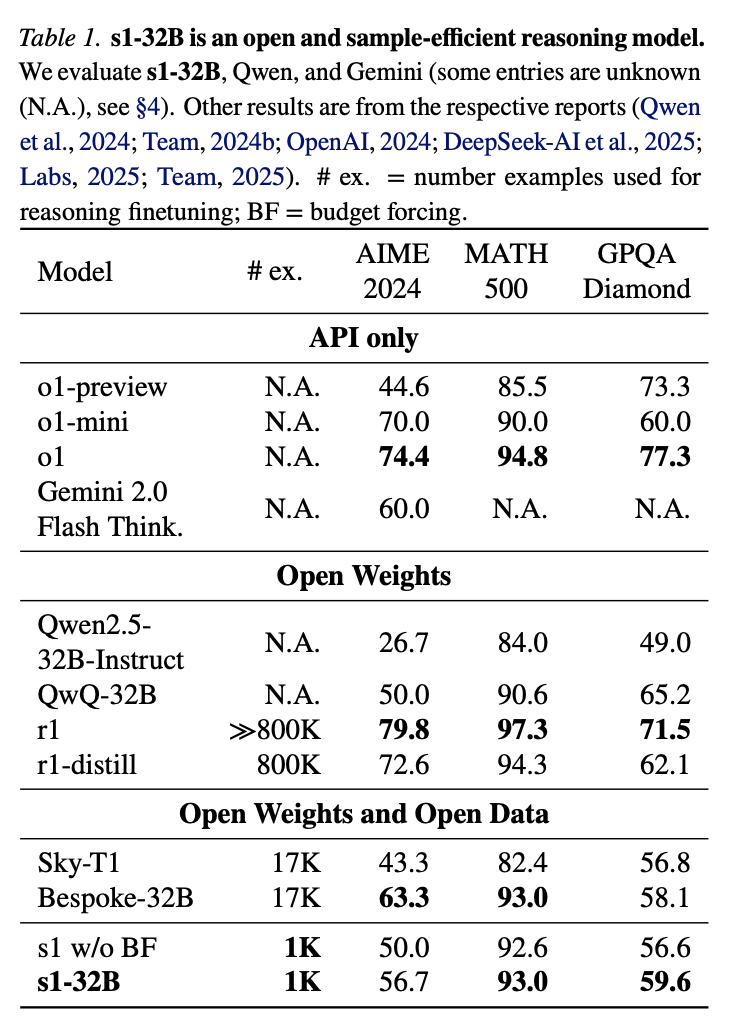
Qwen2.5-32B-Instruct supervised finetuning하고 budget forcing을 적용한 후, 모델 s1-32B는 수학 문제에서 o1-preview를 최대 27%(MATH 및 AIME24) 능가.
1. Introduction
LM은 scaling law에 의존하여 대규모 데이터, 모델, 훈련시간에 의존한 성능을 발휘함. 테스트 타임 스캐일링이 발견되었고 테스트 시간에 계산량을 늘려 더 나은 결과를 얻도록 하는 것임. o1이 이를 보여주었고, MCTS, 다중 에이전트, 기타 방법들이 복제를 해보려 했다. 특히 R1은 o1에 근접한 성능을 보임.
이 연구에서 던지는 질문은 : 테스트 타임 스케일링과 강력한 추론 성능을 모두 달성하기 위한 가장 간단한 접근 방식은 무엇인가?

- 1k의 데이터로 SFT후 budget forcing하는 것
- 1k데이터 : gemini Thinking Experimental에서 추출한 답변, 이떄 1K 데이터는 매우 신중하게 선별됨.
- SFT : 16개 H100 GPU에서 26분 훈련
- Budget forcing : SFT모델을 더 훈련함 -> 성능 좋음(figure 1)
- 모델이 예정보다 더 많이 토큰 생성을 하면, 강제로 <EOS>로 종료
- 모델이 생각하는 토큰보다 더 생성하게 함. <EOS>-><Wait>

- o1-preview보다 더 좋은 성능 달성함.
- 데이터 적인 측면에서, Bespoke 59k의 데이터를 다 사용하는 것보다, 높은 품질로 curating하는 것을 말하고 있음.
2. Reasoning Data Curation to Create s1K (생성 -> 필터링)
2.1 Initial collection of 59K samples
- Quality(고품질), Difficulty(어려워야 함.), Diversity(다양한 분야) 세가지를 만족하는 데이터 59k수집함.
- Curation of Existing Datasets :
NuminaMATH, AIME(1983-2921), OlympicArena, OmniMath, AGIEval - New Datasets in Quantitative Reasoning :
두 개의 새로운 데이터셋을 생성. s1-prob(스탠포트 통계학과 PhD 시험), s1-teasers(quantative 거래 포지션 면접 질문)
각 질문에 대해 Gemini Flash Thinking을 사용해 추론과정과 해결책을 생성. (질문, 추론과정, 해결책)
8-gram 사용해 데이터 중복 제거
2.2 Final Selection of 1K samples
- 목표 : 최소한의 자원으로 최대의 성능을 달성하는 것이라 1K만 사용해 훈련
- Quality : API오류로 생성안된것 제거, 포메팅 문제가 있는것 제거 -> 51,581
-> B.4를 참고하여 384개 추출 - Difficulty : 모델 성능, 추론 과정 길이 두 가지 지표 사용.
- 모델 성능 : Qwen2.5-7B-Instruct, Qwen2.5-32B-Instruct 모두 풀 수 있는 문제는 제거(너무 쉬움)
- 추론 과정 길이 : 긴 추론 과정이 있을 수록 더 어렵다고 가정.
- Diversity : Sonnet3.5를 사용해 각 질문을 특정 도메인으로 분류함.
-> 50개의 도메인으로 분할 (B.4참고)
3. Test-time Scaling
3.1 Method
- Test time scaling
- 1) Sequential : AR하게 긴 추론과정을 생성. -> 이 방법을 채용
- 2) Parallel : 독립적인 샘플링.
- Budget forcing :
- 최대 및/또는 최소 thinking 토큰 수를 제한하는 방법을 제안.
- 최대 토큰 수를 강제하기 위해 : end-of-thinking 토큰 와 "Final Answer:"를 추가하여 thinking 단계를 조기에 종료하고 모델이 현재 최선의 답변을 제공하도록 한다.
- 최소 토큰 수를 강제하기 위해 : end-of-thinking 토큰 생성을 억제하기 위해 "Wait"을 추가하여 더 많은 탐색하도록 한다.(Figure3)
- 최대 및/또는 최소 thinking 토큰 수를 제한하는 방법을 제안.

- Baselines(budget forcing) :
- Conditional length-control 방법
- 1) Token-conditional control : 몇개 토큰내로 생각하세요.
- 2) Step-conditional control : 몇개 스탭내로 생각하세요(스탭은 예를들어 100토큰 내외)
- 3) Class-conditional control : 짧게, 길게 생각하세요
- Rejection sampling : n token이하로, 생성 결과가 나올 때까지 모델을 여러 번 실행함.
- Conditional length-control 방법
3.2 Metrics
test time scaling측정을 위한 평가로는 정확도, 기울기를 고려해야함(figure1)
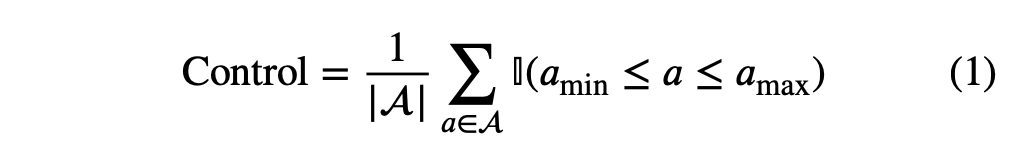
- Control : 사실 왜 중요한지 모르겠음.
- |A| : 테스트 데이터의 수
- I : indicator - $a_{max}$안에 몇개나 생성이 되나, 여기서 $a_{max}$는 실험자가 설정함.
-> 모델이 제안한 계산량 내에서 대답이 끝나야함.
- Scaling : 기울기를 측정 (x축은 thinking수, y는 성능)
- Performance : 벤치마크 성능
4. Result
4.1 Setup
Training : s1K, Qwen2.5-32B-Instruct에 SFT수행. s1-32B를 얻음. (H100 16대로 26분 소요)
Evaluation : AIME24, MATH500, GPQA Diamond
Other Models : o1, r1, QwQ-32B-preview, Sky-T1-32B-Preview, Bespoke-32B, Gemini2.0 Thinking
4.2 Performance

- 그림1 : budget forcing을 사용 -> 토큰수가 많이 생성될수록 성능이 올라감
- 그림4-왼쪽 : 그림1의 중간 부분을 확장한 그림으로, test-time compute사용할수록 성능이 좋아지나, thinking 과정을 6번 이상 연장했을 떄 성능이 평탄해진다. 이는 end-of-thinking 토큰을 너무 자주하면 모델이 추가적인 유용한 추론 대신 반복적인 루프에 ㅈ빠지게 된다.
- 그림4-오른쪽 :두개를 비교
- Sequential scaling(s1-32B + budget forcing) : 모델이 하나의 긴 추론 과정을 통해 답을 찾음
- Parallel scaling(기본 모델 + 다수결 투표) : 여러 개의 독립적인 추론을 생성한 후 가장많이 나온 답을 선택
- Sequential scaling이 더 좋은 성능을 보임.
5. Ablations
5.1 Data Quantity, Diversity, and Difficulty
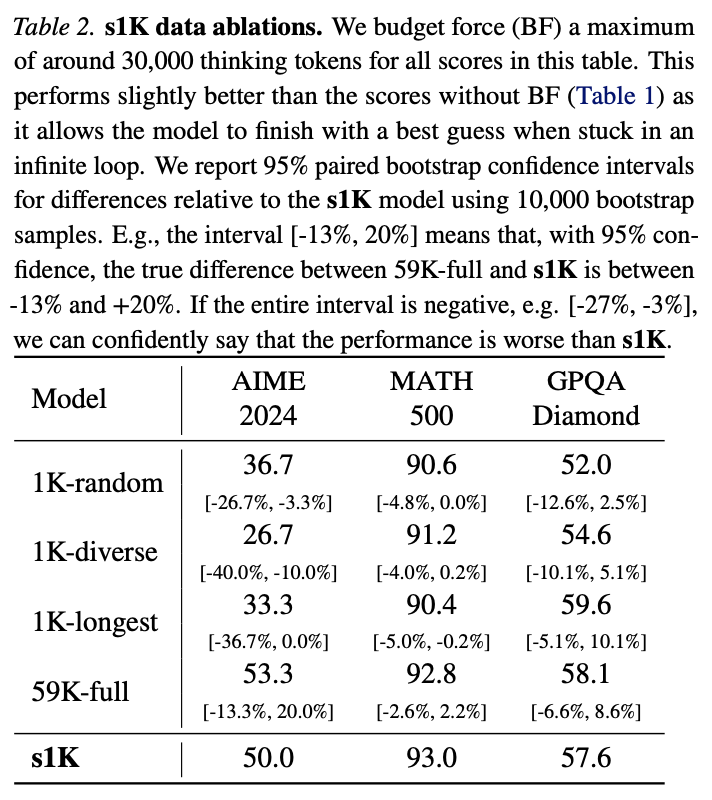
- 품질(1K-random) : Gemini에서 추론 데이터를 얻고, 난이도와 다양성에 의존하지 않고 무작위로 1000개의 데이터를 선택할 경우, 성능이 매우 나빠짐.
- 다양성, 난이도, 많은 데이터등을 위포에서 확인할 수 있음.
- 전체 데이터를 학습할 경우 성능이 많이 올라가나 394 H100 GPU시간이 필요하나, s1은 7 GPU시간이 필요했음.
5.2 Test-time scaling
Budget forcing : 어떤 단어로 할 경우에 가장 좋은 성능을 보였는지 확인. Wait이 가장 좋았음.

Class Condition control : 생략
Rejection sampling : 모델 보고 더 길게 생각하도록 강제하면 오히려 성능이 낮아짐.
-> 더 많은 추론을 하게 되고, 자신의 접근 방식을 되돌아보거나 의심함. 혼란스러운 추론이 누적되어 오답으로 이어질 가능성이 높아짐.

6. Discussion and related work
6.1. Sample-efficient reasoning
6.2. Test-time scaling