주의 : 본 게시글은 저자가 Recap용으로 작성하는 글로서 명확하지 않은 정의와 모호한 설명이 있을 수 있음.
논문요약
UltraGCN은 Regressive한 메시지 전달을 생략하고, Loss 함수를 통해 무한개의 Message Passing Layer를 통과한 값의 근사치를 구한다. 이를 통해 기존 연구들보다 10배 빠른 수렴 속도를 보이며 산업적으로 적용하는데 무리가 없다.
1. 개론
GCN, GNN계열에서 유저와 아이템간의 high-order 연결을 잘 포착함으로 인해 눈부신 성과를 거두었다. 허나 산업적으로 적용하는데 있어 몇가지 제약 사항들이 존재한다.
GCN계열의 기반 모델은 큰 그래프(large graph)에서 학습하기 어렵기에 산업에서 널리 채택되는데 어려움이 있다.
- 많은 고객수와 많은 아이템의 갯수로 인해 좀더 효율성과, 확장성에 문제점이 있다.
- 연구를 통해서 message passing(neighborhood aggregation)에서 많은 시간이 소요됨을 발견하였다.
따라서, 이 연구에서는 message passing에 대한 의문점을 제기하고, 효율적 추천을 위해 message passing이 없는
단순화된 형태의 UltraGCN을 제안한다.
1) Message Passing 과정에서 Edge에 할당되는 가중치는 직관적이지 않아 CF에 적합하지 않을 수 있다
2) Forward를 진행하는데 여러 관계는(사용자-아이템 쌍, 아이템-아이템 쌍, 사용자-사용자 쌍 등) 재귀적으로 결합하지만 다양한 중요도를 포착하지 못한다(학습에 혼란을 주는 노이즈가 및 정보가 없는 관계가 있을 수 있음)
3) OverSmoothing은 LightGCN에서 3개 이상의 Layer를 사용하는데 제약사항을 주었다. 따라서 Encoder를 통해 메시지 전달을 하기보다 Loss를 통해 ultimate 그래프 컨볼루션을 수학적으로 근사치를 구하는 UltraGCN을 제안.
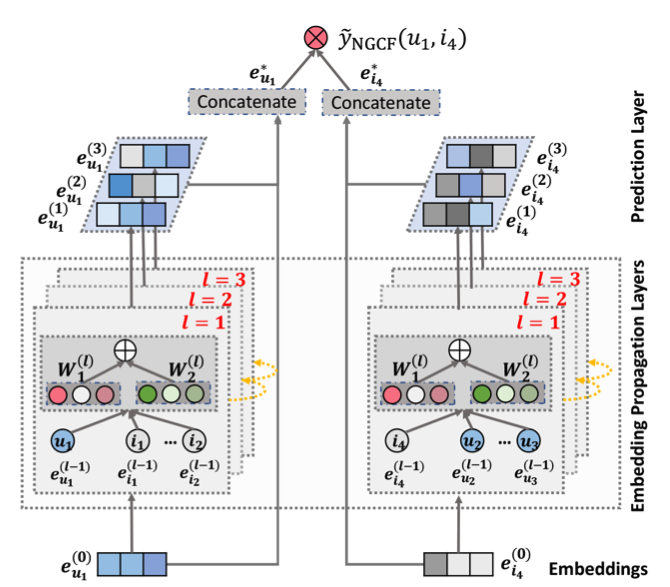
2. GCN, LightGCN 돞아보기

위 그림에서 윗쪽에 있는 부분이 GCN부분이며, 수식으로 표현하면 아래와 같다.
- Sigma : activation
- A : Adjacency Matrix
- D : Diagonal Node Degree Matrix
- A_hat : A + I
- D_hat : D + I
- E : Embedding
- W : Weight

GCN에서 LightGCN으로 변화하면서 Layer를 표현하는 방법은 아래와 같이 바뀌었다.(Self Connect 및 Weight Param제거, 초기의 embedding만 학습 가능). 허나, 임베딩의 가중치 합계를 최종 출력 벡터로 출력하기 때문에 self-loop와 유사한 효과를 내어 아래처럼 표현할 수 있다.
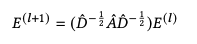
User쪽에서 Layer를 통한 Embedding과정을 자세히 살펴보면 아래처럼 작성할 수 있다.
아래 그림은 User중에 u라는 케이스를 도식화 및 수식화 한것이다.

2.2 Message Passing의 한계점
맨 마지막 레이어에서 User_Emb * Item_Emb을 진행하는데, 3번과 4번 식을 차용해서 표현하면 5오 같은 수식으로 나타낼 수 있다.


이때 알파들은 아래와 같이 표현한다. ( 위 수식을 간단하게 표현하기 위해 알파를 정의함 )

전개된 식을 살펴보면 1)User-Item, 2)Item-Item, 3)User-User 4)(User와 연결된 아이템)-(아이템과 연결된 유저)등의 관계를 포착하는 것을 볼 수 있다. 이때문에 GCN기반 모델이 CF에 효과적인 이유이다. 허나 네가지 유형의 관계에서 할당된 가중치가 CF에서 적합하지 않은 것을 발견하였다.
한계점 1. 가중치 alpha_ik(파란선)는 Item-Item 관계를 모델링하는데 사용되나,
유저 u가 주어졌을 때 item(i)와 item(k)의 가중치가 비대칭적인 문제가 있다.
-> 수식을 뜯어보면, item(i)는 1/(d_i + 1)의 가중치를 부여 받으나, item(k)는 1/sqrt(d_i+1)의 가중치를 부여받는다. 이로 인해 성능의 저하가 있을 수 있다.
한계점 2. Message Passging에서 다양한 유형의 관계를 재귀적으로 결합한다.
- 다양한 유형의 관계를 재귀적으로 결합하면서 GCN이 성공하였으나, 노이즈가 많거나, 불필요한 관계가 발생하는 부분때문에 학습 효율성에 큰 저하를 발생시킬 수 있다.(4.4절에서 다룸) -> it is also pointed at SimpleX
한계점 3. 레이어 수와 high-order signals의 관계를 살펴보면, Over Smoothing의 이슈가 발생함.
- OverSmoothing 이슈로 LightGCN에서도 3번째 레이어까지만 구성함. 동일한 Item을 갖고 있거나, 동일한 User를 갖고 있는 경우 Layer가 많이 쌓일 수록, 동일한 임베딩을 갖게 되게 된다. 아래 식에서 무한번의 Laplacian Smoothing을 할 경우 어떻게 수렴이 되는지 표현한 식으로 동일한 임베딩을 갖는것을 보여준다.

위와 같은 한계점 3가지 때문에, Layer를 통과하는게 명시적으로 필요한지 의문을 제기하고, UltraGCN을 제안한다.
3. UltraGCN
위의 한계점들 때문에, Layer를 통과하는 Explicit한 Learning말고, 궁극적으로 도달하고자 하는 Embedding으로 Mapping 하는 방법이 없을까?
3.1 User-Item Graph
무한개의 Layer를 통과한 유저의 임베딩은 아래와 같이 표현 할 수 있을 것이다.

이를 3번 식에 대입하여 풀이하면 9번식을 유도할 수 있다.

다른 말로 하면, 각각의 노드가 9번의 식을 만족하면 Message Passing이 수렴된 것으로 생각할 수 있다.
우리가 궁극적으로 훈련이 되면 좋겠는 방향은 특정 user embedding과 연관된 edge(item)들의 interaction이 최대는 방향으로 생각해 볼수도 있다.
이를 논문에서는 아래와 같이 표현하였으나

수도 코드로는 아래와 같이 간단하게 표현할 수 있다.(Score가 최대가 되는 방향으로 학습)

위의 수식은 코사인 유사도를 최대화 하는 것과 같은말임. Activation Function인 Sigmoid와 Negative Log likelihood로 표현하면 아래와 같다.

하지만 Loss C 만으로는 문제점이 있다. 2.2절에서 언급한 한계점 중 하나인 OverSmoothing문제를 해결하지 못한다.
위 Loss로 학습할 경우, User와 Item의 Embedding이 비슷한 Representation을 갖을 수 있다.
- LightGCN의 경우, OverSmoothing을 피하기 위해, Layer를 얕게 쌓는 방법을 취함.
OverSmoothing을 피하기 위해, Word2Vec에서 사용하는 Negative Sampling 방법을 차용하였다.

Positive Sample에 대해선 11번 식에서 설명하여 생략하고, NegSample에 대해서 설명하자면
User vector와 Neg Item Vector의 방향 벡터가 다르면 다를 수록 좋다.
따라서 Vector곱이 음수가 나오면 좋은데, 이를 Loss Function에 녹아내기 위해 -를 곱하여 표현하였다.
여기서 Beta_user_item Term은 가중치로 볼 수 있다.
만약 한명의 유저가 많은 Item에 상호작용 하거나, or vise versa한 상황이라면 가중치가 작아야 하는데 이를 Beta가 역할을 수행한다고 보면 된다.
다만, CF문제에서는 일반적으로 BPR Loss를 차용한다. 따라서 이 논문에서도 BPR Loss를 주 Loss Function으로 사용한다.
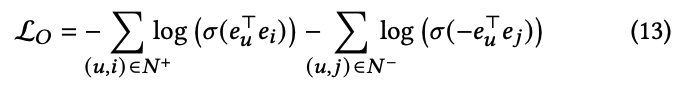
최종적인 Loss는 아래와 같다.

3.2 Item-Item Graph
5번 수식에서 볼 수 있듯 User-Item 관계 외에도 User-User, Item-Item도 GCN CF에서 크게 기여하는 부분이 있다. 그러나 기존 모델들은 User-Item관계와 같은 Layer와 Loss를 통해서 학습 된다. 이로 인해 가중치가 불균형하게 설정될 뿐만 아니라 다양한 관계에 있어 상대적인 중요도를 파악할 수 없다(2.2절 한계점1). 반면 이 연구에서는 명시적인 방법으로 학습하지 않기 때문에 보다 유연한 방법으로 관계별로 학습을 따로 진행할 수 있다.
아이템이 같이 발생한 메트릭스 G를 아래와 같은 방법으로 구한다.

9번 식처럼 유도를 진행하면 아래와 같이 유도할 수 있다.(수학적으로 어떻게 유도 하는지 모르겟다.)

방정식 12와 유사하게, 아이템-아이템 그래프에서 아이템 간의 관계를 학습하기 위한 제약 손실을 유도할 수 있으나 𝐺가 사용자-아이템 그래프의 Adjacency Matrix 𝐴와 비교하여 훨씬 밀도가 높기 때문에, 𝐺에 대한 제약 손실을 직접 최소화하는 것은 신뢰할 수 없거나 노이즈가 많은 아이템-아이템 쌍이 최적화 될 수 있어서 UltraGCN을 훈련하기 어려울 수 있다. 이는 또한 2.2절에서 설명한 기존 GCN 기반 모델의 제한 사항 II와 유사하다. 그러나 UltraGCN의 유연한 설계로 해결이 가능하다.
위에서 나온 W는 아이템 i와 j의 coefficient로 생각할 수 있는데, 간단하게 말하자면 아이템 i와 j의 관계 즉 얼마나 가까운지로 말할 수 있다. 따라서 아이템i 와 동시에 발생한 아이템 j들에 대해서, W기준으로 소팅을하고, 상관성이 가장 높은 k개의 item들을 선택한다.

Item-Item에 대한 Loss는 (17)과 같다. 유저 u와 연관된 Positive Item들 중, w가 높은 k개의 아이템을 선별한다. 유저 u와 아이템들간의 상관성을 구한뒤 Negative Log를 구하는게 Loss Function이다. 여기서 w는 각각의 유저 아이템 쌍의 가중치 역할을 한다.

UltraGCN의 최종적인 Loss는 (18)과 같으며, Lo(BPR), Lc(유저-아이템), Li(아이템-아이템)을 조합한 Loss이다.
3.3 정리
1. UltraGCN에서 엣지에 할당된 가중치 𝛽𝑖,𝑗 및 𝜔𝑖,𝑗는 CF에서 더 합리적이고 해석 가능하여 사용자-아이템 및 아이템-아이템 관계를 더 잘 학습하는 데 도움이 된다.
2. 명시적인 메시지 전달 없이도(Layer를 통과하지 않고도) U잘 작동하며, UltraGCN은 유연성을 가지고 있다. 또한, 모든 이웃 쌍에서 동일하게 학습하는 대신 Section 3.2에서처럼 유용한 훈련 쌍을 선택할 수 있으며 노이즈 데이터를 넣는 것보다 더 좋은 결과를 보여준다.
3. UltraGCN은 다양한 유형의 관계로 다중 작업 학습 방식으로 훈련되지만, (L𝐶, L𝐼, L𝑂)은 BinaryCrossEntropy형식과 비슷하여 훈련이 용이하며 빠르게 수렴한다.
4. UltraGCN의 설계는 유연하다. 𝛾를 0으로 설정하면 BPR을 사용 안하게 되며 (UltraGCN Base) 사용자-아이템 그래프에서만 학습한다.
UltraGCN에 User-User 관계를 모델링 하지 않는다. 주로 User의 특성이 아이템의 특성보다 훨씬 더 다양하기 때문이다. 우리는 User-User 공존 그래프에서 User-User 관계를 캡처하는 것이 어렵다는 것을 발견함. 뒤에서 User-User 공존 그래프에서의 학습이 UltraGCN에 현저한 개선을 가져오지 않는다는 것을 경험적으로 보여준다. 반면, 기존의 GCN 기반 CF 모델은 User-Item 그래프에서 모든 관계를 구별하지 않고 학습하기 때문에(즉, Limitation II), 성능 저하를 겪을 가능성이 있다. User-User 관계는 소셜 네트워크 그래프에서 더 잘 모델링 될 수 있으며, 이 부분은 향후 연구로 남겨둔다.
다른 모델과 UltraGCN의 관계성을 비교하는 섹션이 있으나 생략하겠다.
- Relation to MF
- Relation to Network Embedding Method
- Relation to One-Layer LightGCN
4. 실험
파라미터
- Learning Rate : 1e-4
- Batch_size : 1024
- NegSample : 300
- K : 10
- Embedding_dim : 64
- 𝜆 : [0.2, 0.4, 0.6, 0.8, 1.0, 1.2, 1.4]
- 𝛾 : [0.1, 0.5, 1.0, 1.5, 2.0, 2.5, 3, 3.5]