0. Abstract
Mixture of Experts(MoE)는 각 입력 예제에 대해 다른 파라미터를 선택
- 매우 큰 매개변수를 갖고 있으나, 일정한 연산 비용을 가진 희소하게 활성화된 모델이 된다(The result is a sparsely activated model with an outrangeous number of parameters but a constant computational cost)
Switch Transformer의 도입으로
- (MoE)의 단점인 복잡성, 비용, 훈련 불안정성을 개선
1. Introduction
성공한 알고리즘 : Transformer (Vaswani et al., 2017)의 모델 크기를 확장 하는 것이나 계산 집약적이다
이 연구에서는 Switch Transformer를 제안한다.
2. Switch Transformer
- 규모의 이점 : 모델 크기, 데이터 세트 크기 및 계산 예산과의 거듭제곱 법칙 스케일링에 대해 연구 되었음
-> 모델의 크기가 커질수록 성능이 좋아짐.
이 연구에서는 네번째 축을 조사
플롭(FLOPs) : increase the parameter count while keeping the floating point operations (FLOPs) per example constant.
- 토큰을 일정하게 유지하면서 매개변수 수를 늘리는 것
- 이 연구의 가설은 수행된 총 계산과 무관하게 매개변수 수 자체가 확장해야 할 별도의 중요한 축이라는 것이다.
- GPU와 TPU와 같은 밀집 행렬 곱셈을 위해 설계된 하드웨어를 효율적으로 사용하는 희소 활성화 모델을 설계함으로써 이를 달성한다.

2.1 Simplifying Sparse Routing

- 2017년 Shazeer et al의 연구에서 NLP에서 MoE layer를 제안함.
(위 연구가 최초는 아님 1991년 Hinton교수님이 RNN계열 MoE를 제안하긴 했음) - 이 논문에서는 라우터라는 개념이 등장
- 라우터 : 토큰이 여러 FFN중 어느 FFN으로 가야 좋은지 판단함. (Figure2)에서도 Switching FFN Layer에서 여러 FFN이 있는 것을 볼 수 있음.
- 위 논문에서는 Top N개의 expert를 선택함. (by using P_i which is softmax)
- 확률값이 높은 N개의 Expert를 선택해서, 가중치를 주고 더하므로 사실상 여기서도 attention을 한것이라고도 볼 수 있음.(2번식)
- 과거 연구에서는 K개가 2 이상인 것이 중요하다는 연구들이 있으나, 본 연구에서는 k를 1로 설정한다. 이 단순화가 모델 품질을 유지하고, 라우팅 계산을 줄이며, 더 나은 성능을 발휘함을 보여준다.
- 토큰을 단일 전문가에게만 라우팅하므로 라우터 계산이 감소
- 통신 비용이 감소. figure3을 살펴보면 expert별로 할당 될 수 있는 수가 한정되는 모습을 보여주는 예시
- 예를들어) K개의 Expert를 선택할 경우, 데이터를 K배로 복사해야 하여 계산량이 올라가나, K를 1로 할 경우 데이터 그대로 계산을 진행하므로 계산량이 많지 않음.

(total_token/num_experts)*capacity_factor을 통해서, expert별로 고르게 토큰을 할당하려고 하였다.
figure3의 왼쪽 그림을 보면, 빨간색 화살표가 있는데, 해당 expert에 추가적인 토큰 할당을 막는 모습임을 볼 수 있다.
이를 통해 한쪽의 expert에 몰리지 않게 함으로서, 계산 효율성(속도)를 높임.
A Differentiable Load Balancing Loss.
Expert한테 고르게 분포하게 하기 위해 Loss를 설계함. 아래 Loss는 기존 Loss(CrossEntropy혹은 NLL)에 추가되는 Loss이다.

- B : Batch
- T : Token in Batch
- N : Number of Experts
- f_i : expert i에 디스패치되어진 token의 비율
- p_i : expert i 에 할당된 라우터 확률의 비율
- alpha : 기존 Loss를 압도하지 않을 정도의 가중치, 0.01을 사용
Loss가 최소화 되는 방향으로 학습을 진행할 것으로 f_i, p_i가 최소화 되는 방향으로 학습되야 한다.
-> f_i의 최소화 : expert 마다 할당된 token의 비율이 비슷해야 최소화
-> p_i의 최소화 : 하나의 뛰어난 expert에 할당되는 비율이 없어야함.
2.3 Putting It All Together: The Switch Transformer
- Colossal Clean Crawled Corpus 사전 학습으로 시작
- Masked Language Model : 사전 학습 목적으로, 누락된 토큰을 예측. 15%의 토큰을 제거하고 마스킹된 시퀀스를 단일 센티넬 토큰으로 대체
- negative log perplexity성능을 기록. 본 논문의 모든 표에서 ↑는 해당 메트릭의 값이 클수록 좋고, ↓는 그 반대임을 나타낸다.
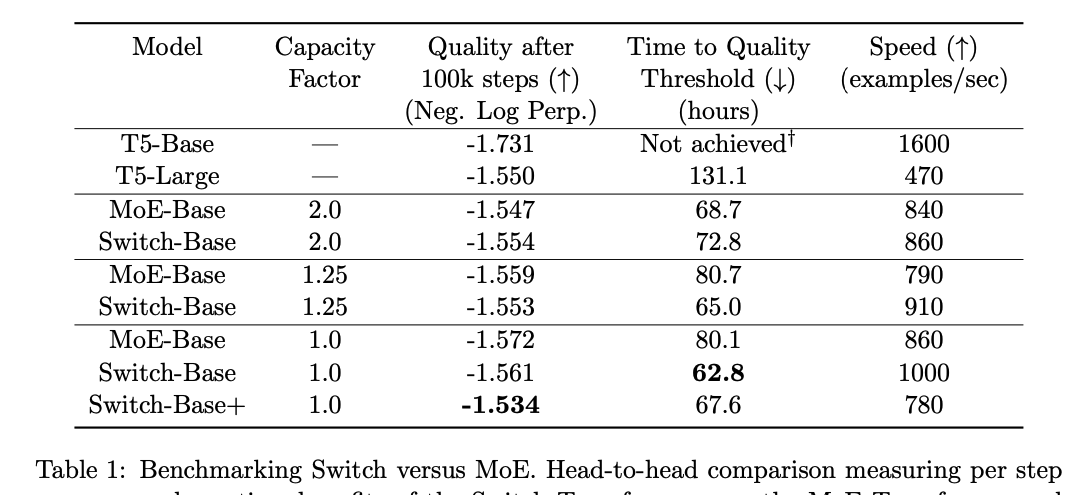
- 과거 연구에선 Capacity Factor가 2이상일 때 좋은 성능을 보인다 하였으나, Balancing Loss를 넣은 K=1일 때 성능이 더 좋았음.
2.4 Improved Training and Fine-Tuning Techniques
Selective precision with large sparse models.
- 해당 연구는 학습이 잘 안되는 문제가 있다(라우팅 으로 인해 불안정성이 발생할 수 있다)
- bfloat16과 같은 낮은 정밀도 형식은 라우터의 softmax 계산 문제를 악화시킬 수 있다
- 모델의 일부분에서 선택적으로 float32 정밀도로 캐스팅하여 학습의 안정성과, 효율성 둘다 챙겼다.
import mesh tensorflow as mtf
def router(inputs, capacity factor):
"""Produce the combine and dispatch tensors used for sending and receiving tokens from their highest probability expert. """
# Core layout is split across num cores for all tensors and operations. # inputs shape: [num cores, tokens per core, d model]
router weights = mtf.Variable(shape=[d model, num experts])
# router logits shape: [num cores, tokens per core, num experts]
router logits = mtf.einsum([inputs, router weights], reduced dim=d model)
if is training:
# Add noise for exploration across experts.
router logits += mtf.random uniform(shape=router logits.shape, minval=1−eps, maxval=1+eps)
# Convert input to softmax operation from bfloat16 to float32 for stability.
router logits = mtf.to float32(router logits)
# Probabilities for each token of what expert it should be sent to.
router probs = mtf.softmax(router logits, axis=−1)밑에서 세번째 줄 : router의 확률값을 float32로 변환한뒤, softmax로 router의 확률값을 계산하는 것을 볼 수 있음.
이후 중간 과정의 계산을 충분히 한 뒤 아래와 같이 bfloat16으로 재 변환함.
# combine tensor used for combining expert outputs and scaling with router probability. # combine tensor shape: [num cores, tokens per core, num experts, expert capacity] combine tensor = (
expert gate ∗ expert mask flat ∗
mtf.one hot(expert index, dimension=num experts) ∗
mtf.one hot(position in expert, dimension=expert capacity))
# Cast back outputs to bfloat16 for the rest of the layer.
combine tensor = mtf.to bfloat16(combine tensor)
이 연구에서 진행한 Selective Precision으로 Quality 및 Speed모두 챙긴 것을 확인할 수 있다.
Smaller parameter initialization for stability
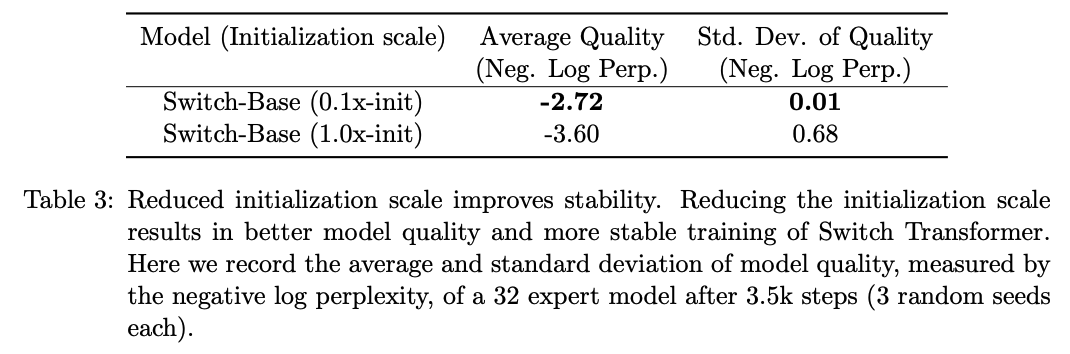
- 저자는 적절한 초기화가 중요하다 언급하였음
- 불안정성에 대한 추가 해결책으로,기본 Transformer 초기화 스케일 s = 1.0을 10배 줄여 실험
- 품질을 개선하고, 실험에서 불안정한 학습 가능성을 줄인다
기타 Experiments results
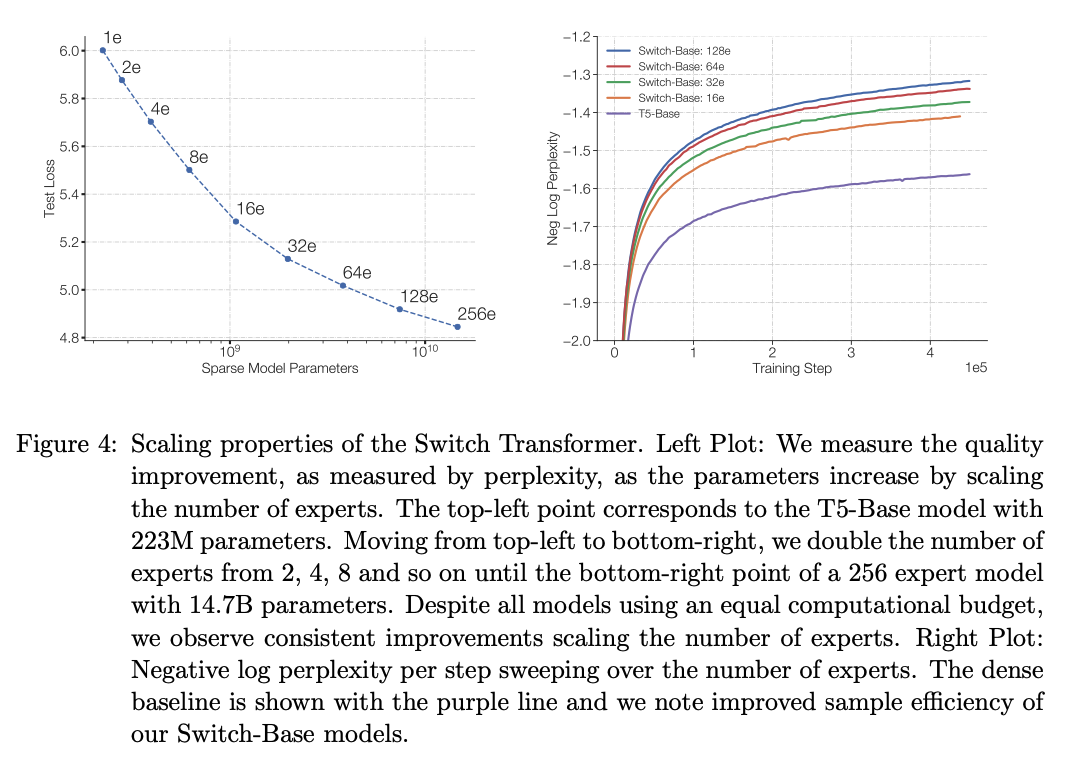
- 왼쪽 그림 : 모델의 파라미터 수가 클 수록 Loss 감소 -> Scale Matters
- 오른쪽 그림 : 큰 모델(Switch)가 더 짧은 시간(iteration)동안 Loss가 더 많이 감소함
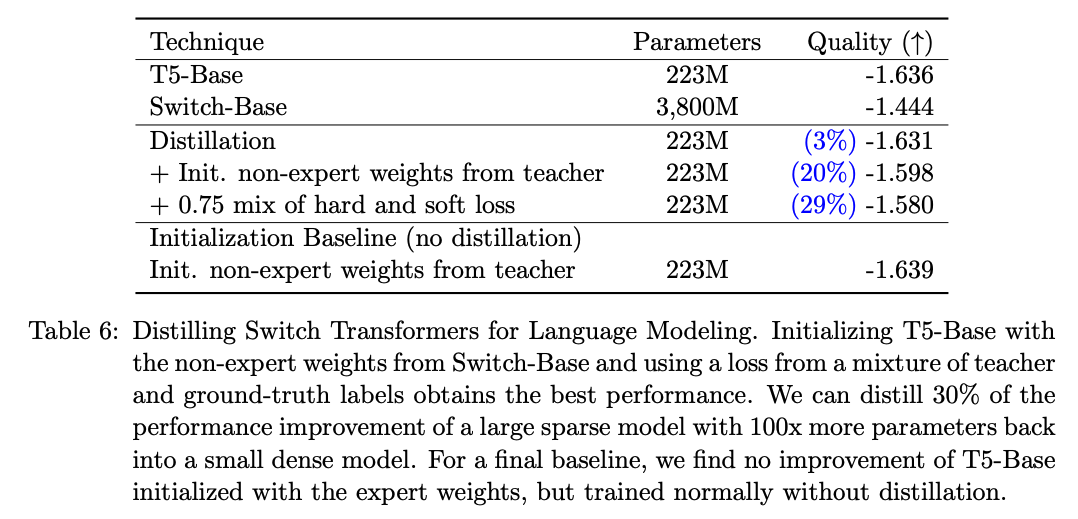
큰 모델인 Switch-Base를 만들고 -> Distilation to 223M으로 하였을 때, T-5 223M과 비교해보면, 30%의 성능이 더 좋아짐.
개인적인 사견 : 같은 파라미터 수를 갖고 있더라도, 더 좋은 Space or Global Minimal에 도달 할 수 있음.