GQA에 들어가기에 앞서,
어텐션에 무엇이 존재하는지 알아보자.
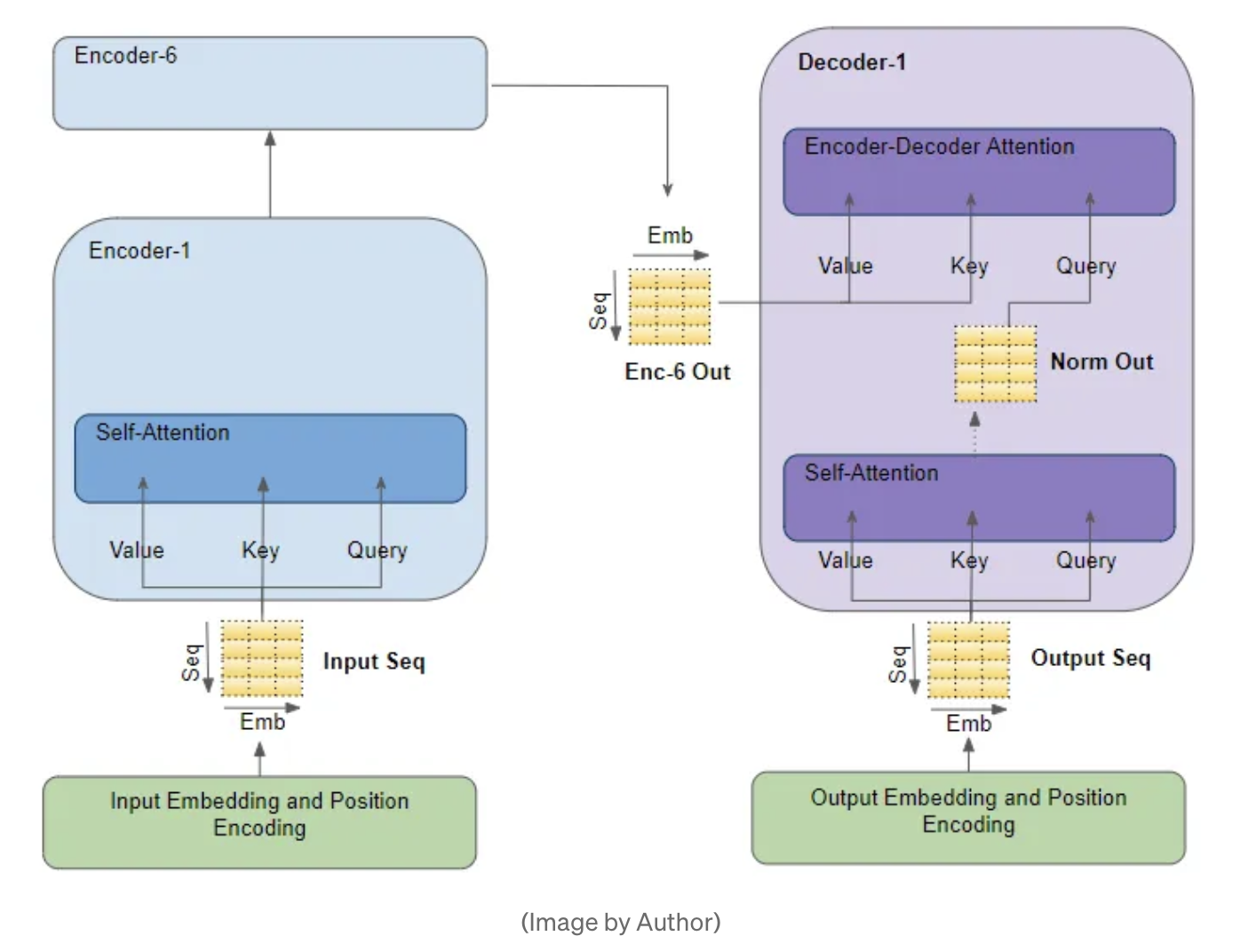
Attention Is All You Need에 언급되었던 Multi Head Attention (2017)
- AI산업 전설의 시작이 되는 컨셉으로, 이후에 vision, anomaly, recommend, audio 모든 영역으로 퍼져나감
- 단점 : 계산의 bottleneck 현상이 발생할 수 있고, computational resource를 매우 많이 잡아먹는 작업이다.
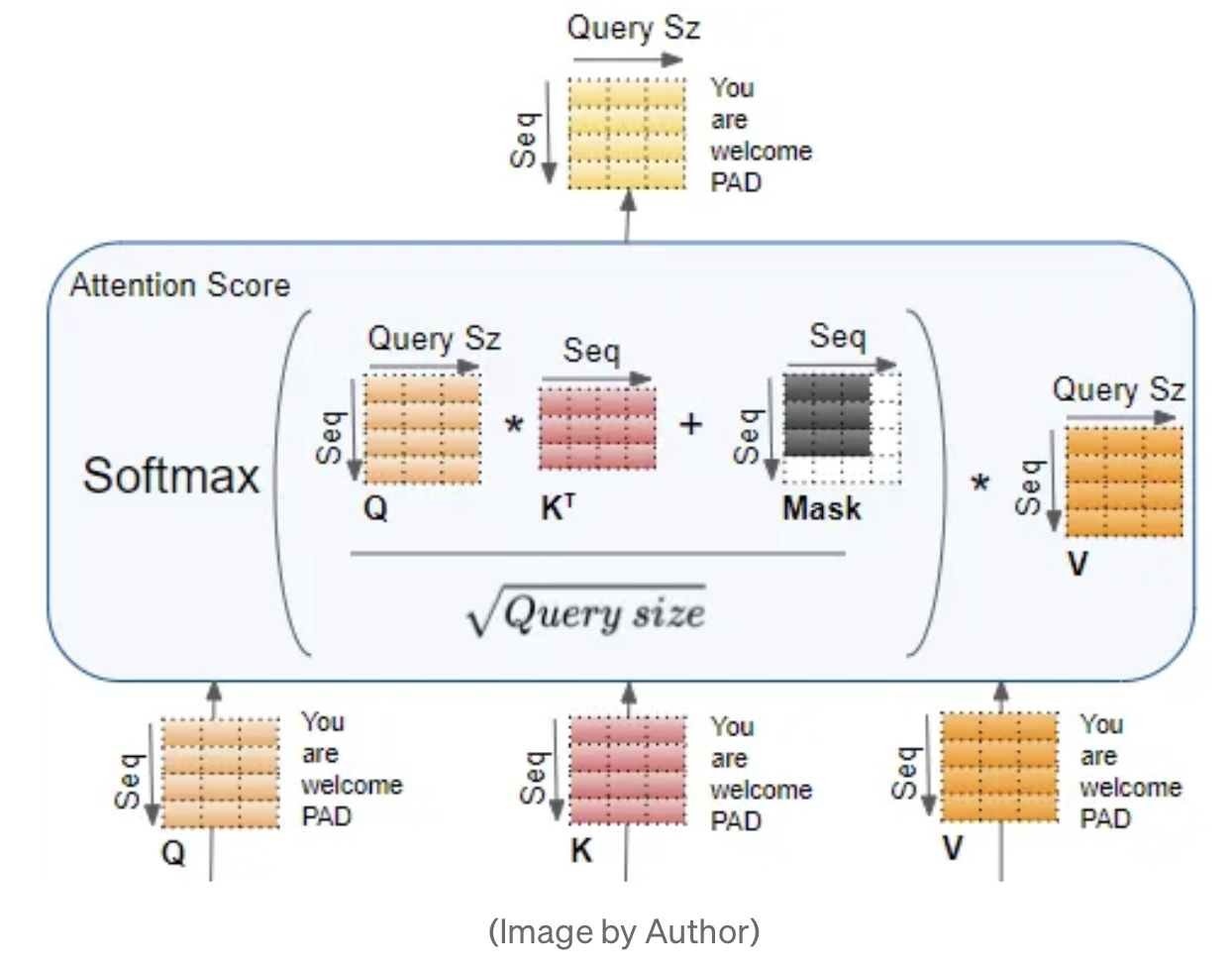
KV cached Attention
- Inference시에 AutoRegressive하게 추론을 진행
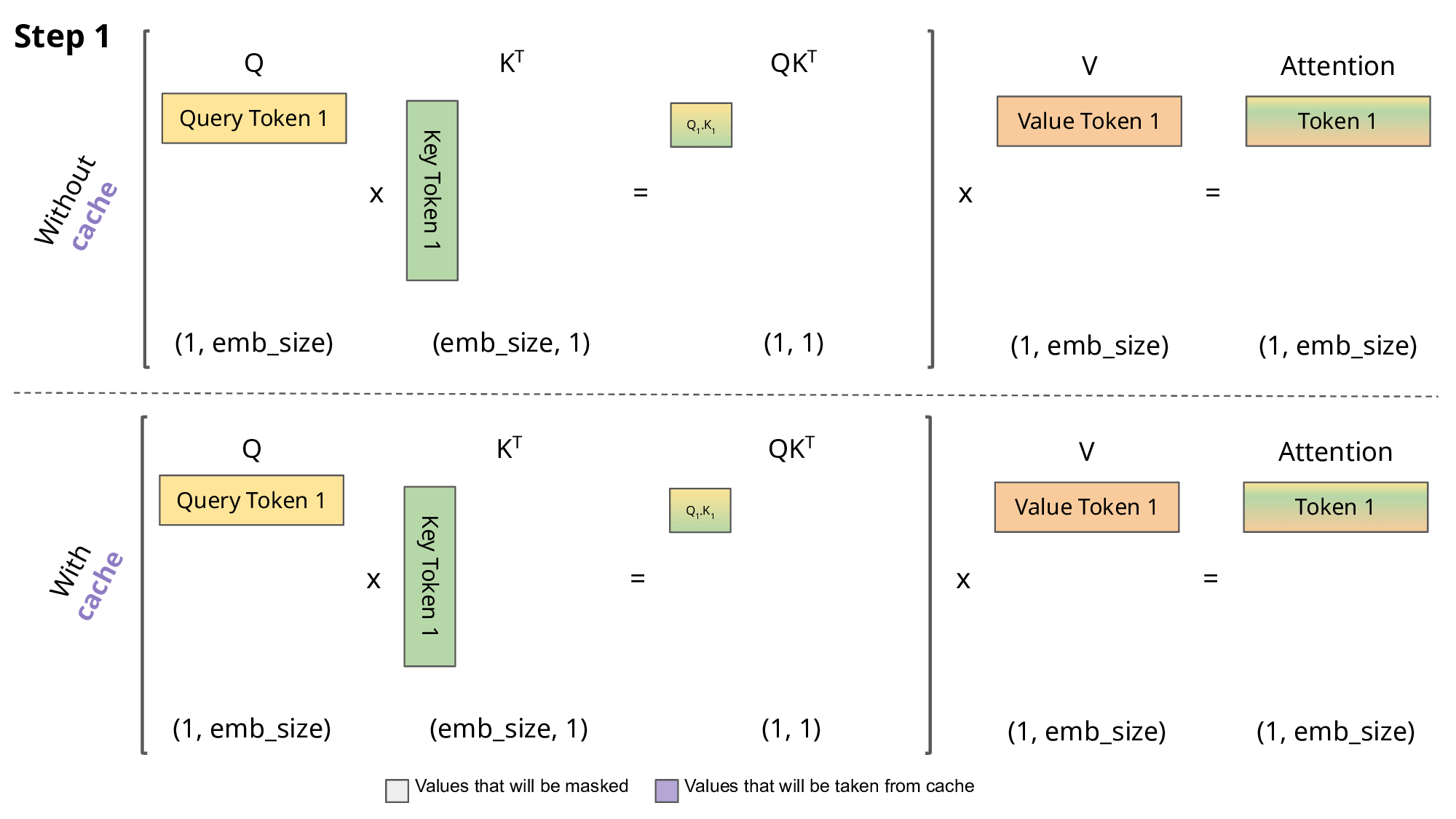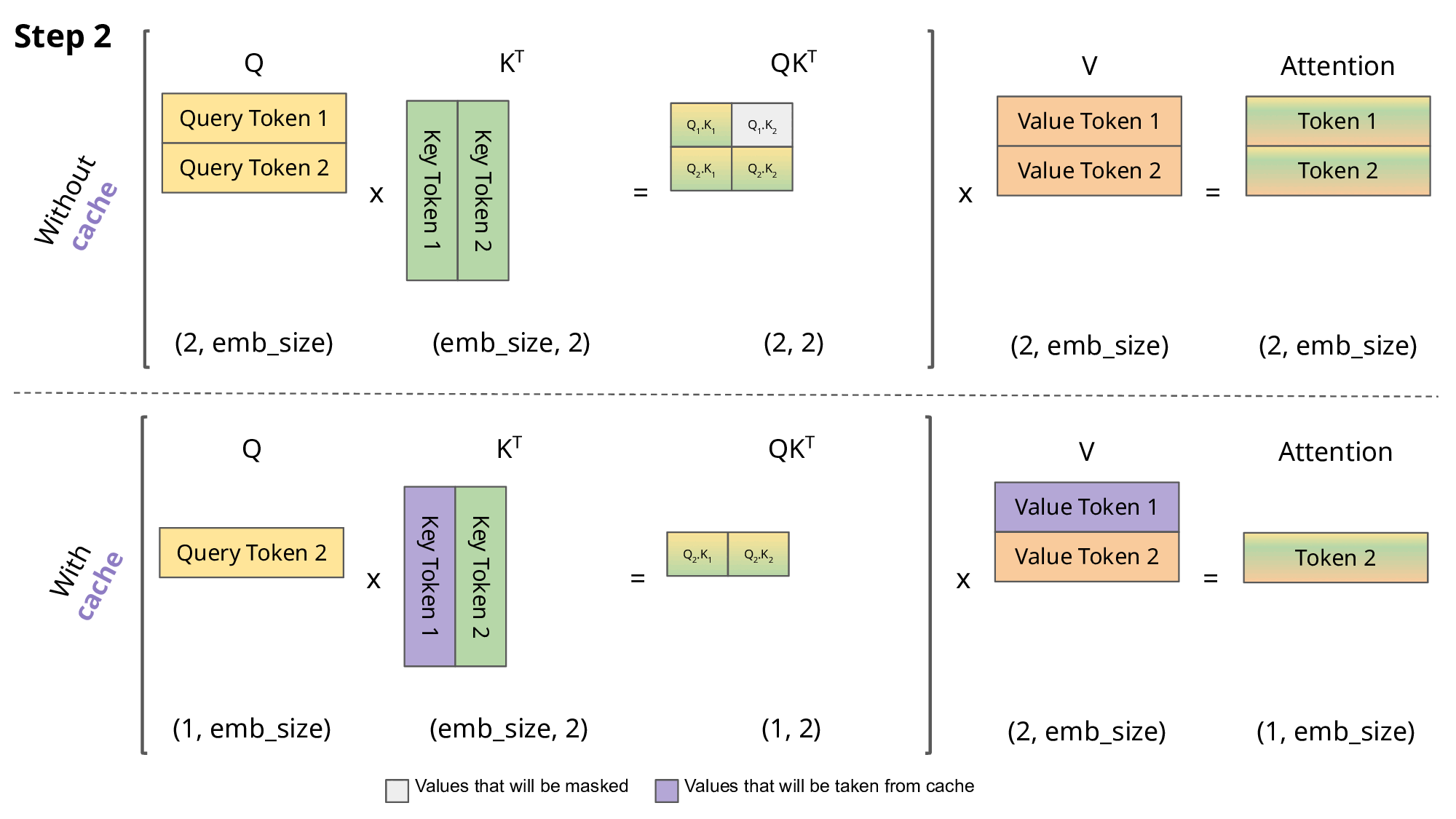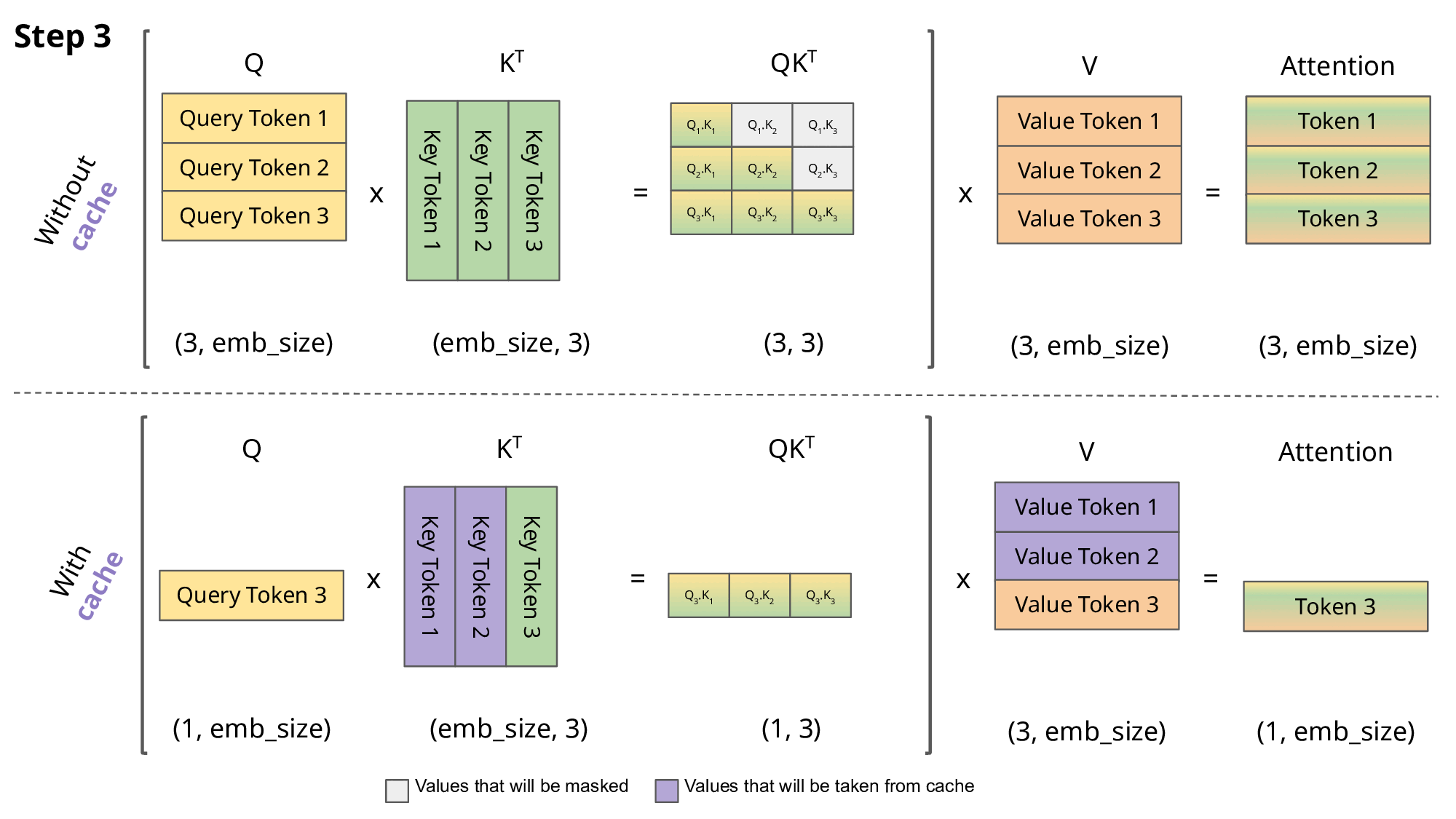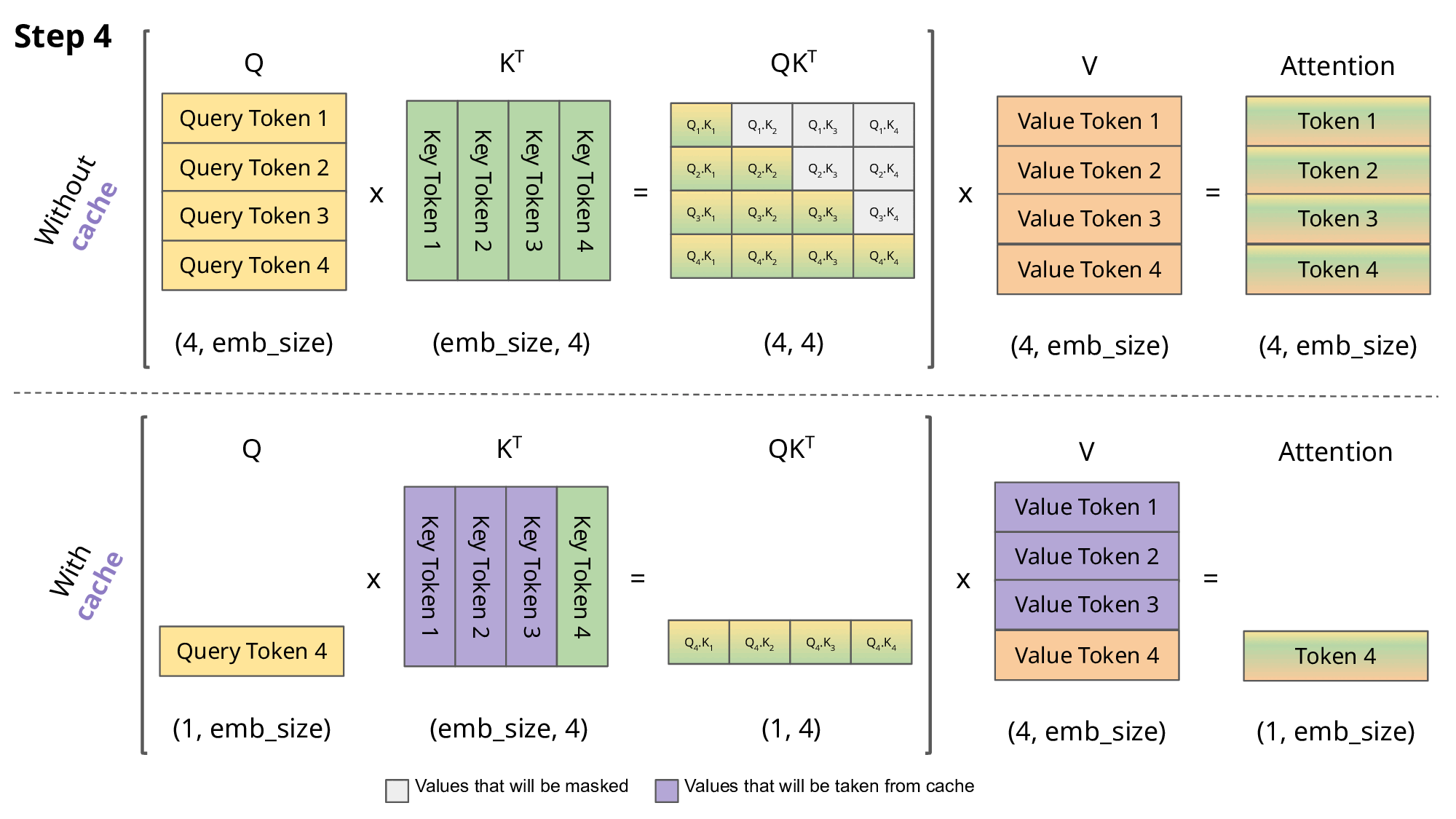
- 위 그림에서, without cache 버전을 살펴보면 매 Inferece시점에서 과거에 계산한 QK를 다시 반복해서 수행해야 한다. (이미 과거에 추론한 데이터는 바꿀 수 없는데 말이다)
- 따라서 아래 제안한 with cache버전은, 이미 지나간 key는 계산하지 않고 저장해둔다. query에서는 해당 시점의 쿼리만 가져와서 계산을 해준다
- 단점 : key들을 어디 저장을 해두어야 하는데, 이로인해 seq길이가 길어지면 메모리에 저장되는 용량이 커져서 문제가 된다.
Multi Query Attention : Fast Transformer Decoding : One Write-Head is All You Need(2019, google)
- K,V에는 MultiHead를 적용하지 않고, Query에만 적용한다.
- 장점 : 이로인해 퍼포먼스는 증가하고, 모델의 성능은 아주 적게 감소하였다.
- 추론에서 11배 빠른 처리량과, 30%더 낮은 대기시간을 얻었다.
- 단점 : Multi Head Attention에 비해 성능이 저하될 위험이 있고, 학습이 불안정하다.
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
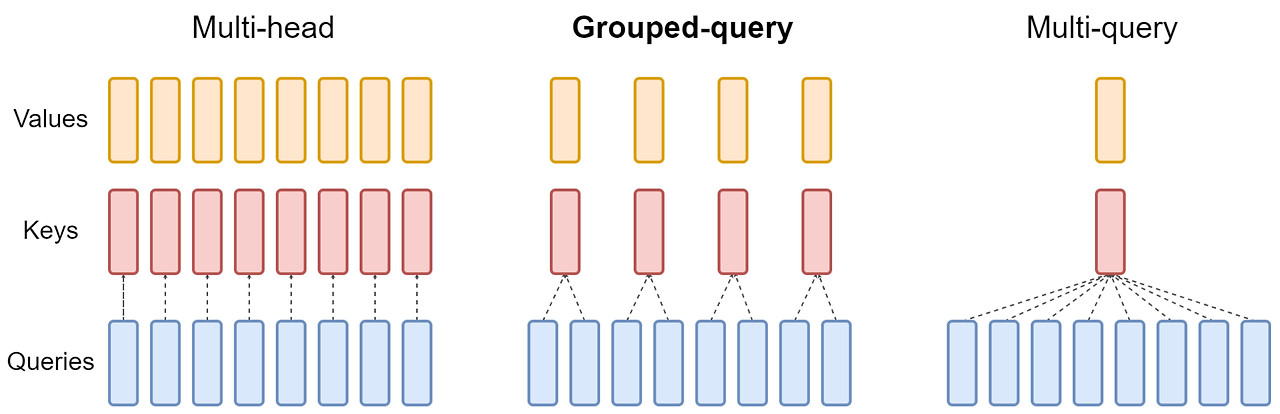
가운데 있는 그림이 GQA로, MHA와 MQA을 섞어 놓은 버전으로 생각하면 좋다.
연구 결과
- Multi-head attention(MHA)이 있는 언어 모델 체크포인트를 multi-query attention (MQA)를 사용하도록 업트레이닝하는 방법을 제안. 빠른 inference와 고품질 체크포인트를 얻는 비용 방법
- Grouped-query attention (GQA)이라는 새로운 방법을 제안. GQA는 query head의 하위 그룹당 하나의 key와 value head를 사용하여 MHA와 MQA를 보완. 업트레이닝된 GQA는 MQA만큼 빠르면서도 MHA에 가까운 품질을 달성할 수 있다.
import torch
import torch.nn.functional as F
from einops import rearrange, einsum
# [batch, seq_len, num_heads, head_dim]
query = torch.randn(1, 256, 8, 64)
key = torch.randn(1, 256, 2, 64)
value = torch.randn(1, 256, 2, 64)
# number of heads in one group, in this example 2 kv_heads
# -> it will be 2 groups of size 4 each
num_head_groups = query.shape[2] // key.shape[2] # 8 // 2 -> 4
scale = query.size(-1)**0.5
# swap seq_len with num_heads to accelerate computations
query = rearrange(query, 'b n h d -> b h n d')
key = rearrange(key, 'b s h d -> b h s d')
value = rearrange(value, 'b s h d -> b h s d')
# split query num_heads in group by introducing additional 'g' dimension
query = rearrange(query, 'b (h g) n d -> b g h n d', g=num_head_groups)
# calculate attention scores and sum over the groupb dim to perform averaging
scores = einsum(query, key, 'b g h n d, b h s d -> b h n s') # g는 broadcasting되어 계산고, average됨
# scores[b, h, n, s] = Σ(query[b, g, h, n, d] * key_broadcasted[b, g, h, s, d])
# reference of einsum https://haystar.tistory.com/93
attention = F.softmax(scores / scale, dim=-1)
out = einsum(attention, value, 'b h n s, b h s d -> b h n d')
out = rearrange(out, 'b h n d -> b n h d')
https://arxiv.org/pdf/2305.13245
https://medium.com/@joaolages/kv-caching-explained-276520203249
Transformers KV Caching Explained
How caching Key and Value states makes transformers faster
medium.com
Long Context로 인한 Large KV Cache의 문제점과 해결 방안: Part I-KV cache의 메모리 요구량
Auto-regressive 모델이란 이전 단계의 출력들을 이용하여 다음 단계의 출력을 예측하는 모델이다. GPT는 auto-regressive 모델로 이전에 생성된 토큰를 기반으로 다음 토큰을 생성한다. GPT는 이전 토큰
moon-walker.medium.com
https://r4j4n.github.io/blogs/posts/kv/
Transformers Optimization: Part 1 - KV Cache
Understanding KV Cache, its working mechanism and comparison with vanilla architecture.
R4j4n.github.io
https://medium.com/@plienhar/llm-inference-series-4-kv-caching-a-deeper-look-4ba9a77746c8
LLM Inference Series: 4. KV caching, a deeper look
In this post, we will look at how big the KV cache, a common optimization for LLM inference, can grow and at common mitigation strategies.
medium.com
https://medium.com/@maxshapp/grouped-query-attention-gqa-explained-with-code-e56ee2a1df5a
Grouped Query Attention (GQA) explained with code
In this short article, I will explain the idea behind GQA and how to translate it into code.
medium.com
'DeepLearing > MileStones' 카테고리의 다른 글
| [논문리뷰] RoFormer : Enhanced Transformer With Rotary Position Embedding (0) | 2024.05.15 |
|---|---|
| [CodeBook (feat. wav2vec2)] CodeBook a.k.a. Quantization (0) | 2024.03.20 |