ASR SOTA모델 중 하나인 Wav2vec2 논문을 살펴보며, CodeBook, Quantization이라는 개념이 나오고, 잘 와닿지 않아 정리해본다.
왜... 왜 이산화를 해????? 정보가 많이 사라질텐데..?
이산화를 하는 이유는 인간이 발음할 수 있는 음소의 수가 한정되어 있기에 CodeBook을 사용한다고 한다
(물론, Continuous -> Discrete화 -> Continuous 하여 사용하는 것만은 아니다.)
(...모델 경량화 할 때 사용된다고 한다.)
(...GumbleSoftmax를 찾아보면 좋겠다.)
(...Continuous -> Discrete 화 하면, 코드 관점에서는 torch graph가 깨지고, 학문적 관점에서는 샘플링을 하는 것과 같기에 reparameterize trick과 같은것이 필요하다. -> 이것을 gumbleSoftmax로 풀어냄)
Feature Extracted된 부분이 Encoder 및 CodeBook으로 따로 흘러가며, 나중에 Concatenate을 하게 된다.
그렇다면 CodeBook은 어떻게 진행될까?
구체적으로 코드와 같이 살펴보자
wav2vec2를 기준으로 설명하자면
## shape들 ##
input_mfcc.shape = [bs, seq_len, feature] # wav -> mfcc 변환
input_mfcc_cnn.shape = [bs, seq_len, cnn_feature] # mfcc -> cnn encoder로 특징 추출
input data가 mfcc 및 cnn으로 위와같이 변환된다.
이때 input_mfcc_cnn데이터가 FeatureExtractor(Masking 처리된 부분)과 CodeBook으로 흘러가게 된다.
여기서는 CodeBook부분만 살펴보자.
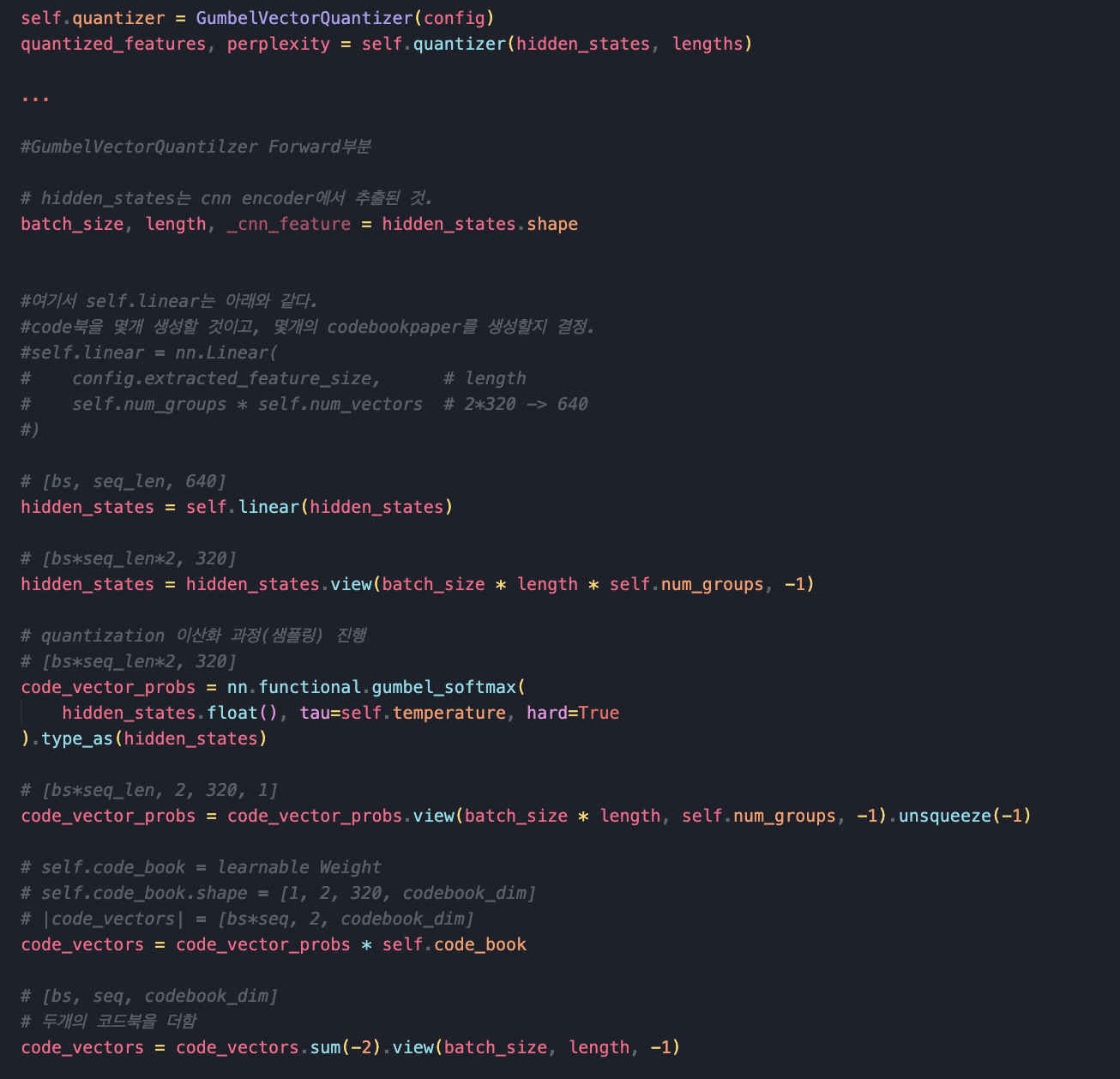

추후 GumbleSoftMax에 대해서 다루겠다.. 이만...
source code
https://github.com/HarunoriKawano/Wav2vec2.0
GitHub - HarunoriKawano/Wav2vec2.0: Implementation of the paper "wav2vec 2.0: A Framework for Self-Supervised Learning of Speech
Implementation of the paper "wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations" in Pytorch. - HarunoriKawano/Wav2vec2.0
github.com
gumble softmax
https://data-newbie.tistory.com/263
[ Python ] gumbel softmax 알아보기
도움이 되셨다면, 광고 한 번만 눌러주세요. 블로그 관리에 큰 힘이 됩니다 :) 예전에 gumbel softmax 관련 영상을 보고 관련된 자료도 찾아봤자만, 이해가 안 됐고 당시에 코드도 Tensorflow로 많이 없
data-newbie.tistory.com
https://kaen2891.tistory.com/81
Gumbel-Softmax 리뷰
본 논문은 2개를 확실히 다 읽어야 이해가 가능한데, [1] [2] 이다. Overview Gumbel-Softmax는 간단하게 정리하면 아래와 같다. 1) sampling을 하고 싶은데, neural network에서 backpropagation시에 불가능하다. 이를
kaen2891.tistory.com
'DeepLearing > MileStones' 카테고리의 다른 글
| [논문리뷰] RoFormer : Enhanced Transformer With Rotary Position Embedding (0) | 2024.05.15 |
|---|---|
| [논문리뷰] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints (0) | 2024.04.28 |