
0. Abstract
일반적인 추론에서 프리트레인 모델의 유연성을 유지함과 동시에 외부 정보를 사용하는게 유익한지에 대해서는 아직 미해결되었다. 이에 답하기 위해 이 연구에서는 언어모델로 생성된 generated knowledge prompting을 개발하고 이는 다음 질문 답변시 모델의 인풋으로 입력된다. 이 연구는 knowlege 통합 혹은 구조적 knowlege에 접근하거나 task specific한 방법은 아니다. 그럼에도 불구하고 최첨단 모델의 성능을 개선하고, 숫자, 일반 상식, 과학적 데이터 벤치마크에서 SOTA를 달성하였다.
1. Introduction
commonsense 추론을 하는데 외부 지식을 사용하는것이 필요한지에 대해서는 아직 의견이 분분하다.
- 긍정론 : 특히 전문가 수준의 지식일수록 도움이 된다.
- 부정론 : 최근 리더보드의 대부분은 대규모의 사전 훈련 모델에 의해 랭킹 되며 모델의 크기가 커질수록 외부 지식을 사용하는것에 대한 강점이 사라진다라고 주장한다. 기존 방식은 지식을 통합하는데 업무별(task) 맞춤형 튜닝이 필요하기에, 사전 학습 모델을 다양한 업무에 빠르게 적용하는게 어렵다.
이 연구는 외부 지식이 사전훈련 모델에서도 추론이 도움되는지 연구하였고, 추가적으로 파인튜닝을 통하지 않고 쉽게 적용할 수 있는 방법을 제안한다. 결론적으로 이 연구는 정보 검색 기반 시스템과 비슷한 수준의 성능을 보인다.
generated knowledge prompt 성능에 영향을 미치는 세가지 요소를 발견했다.
1. 지식의 품질
2. 지식의 양 : 지식 문장의 수가 늘어나면 향상된다.
3. 추론 중 지식을 통합 : 추론 중에 지식을 통합하는 전략
2 Generated Knowledge Prompting

첫번째 단계 : Knowledge generation - 아래 그림에서 Pg에 해당한다.
두번째 단계 : Knowledge Integration - 아래 그림에서 a에 해당한다.
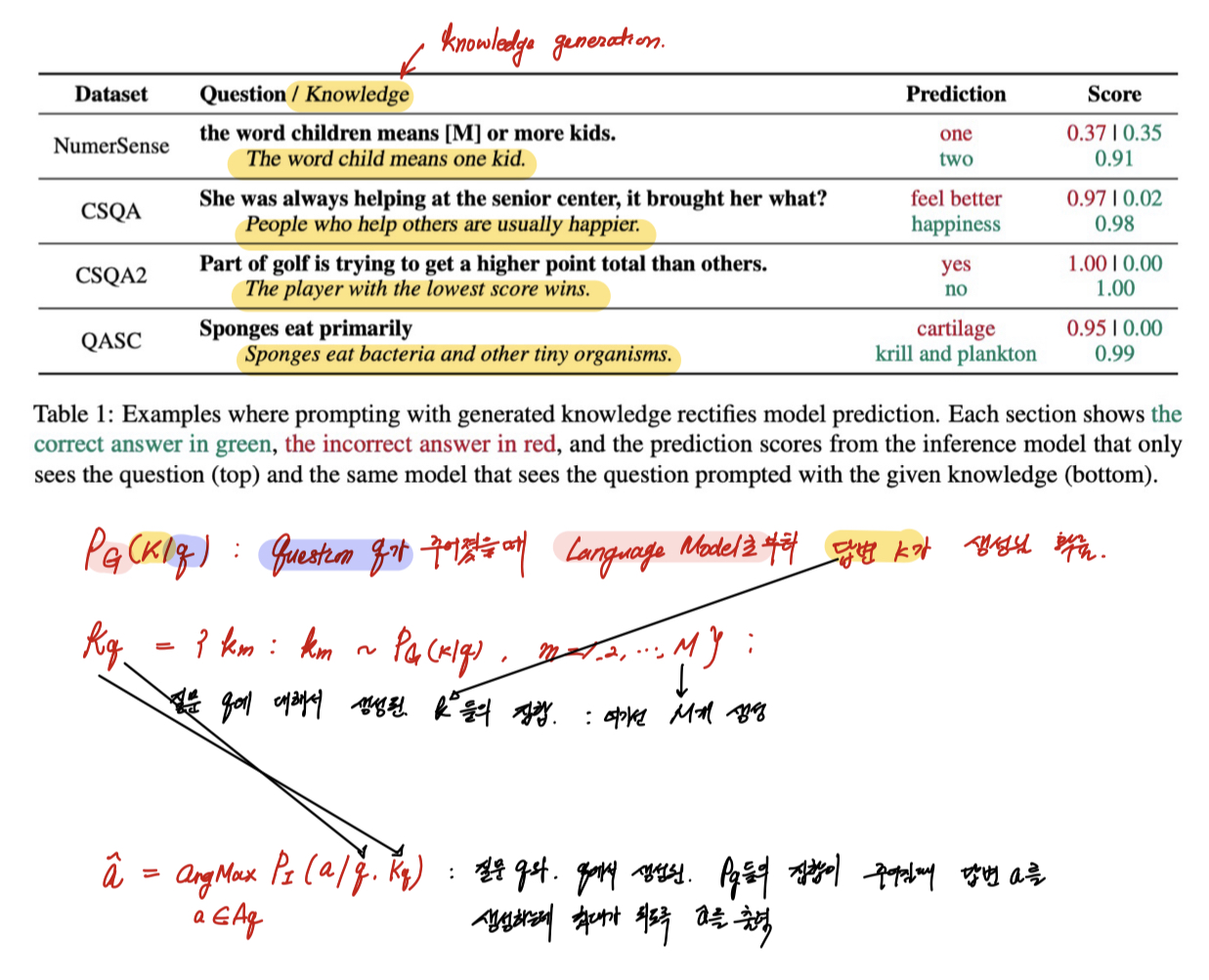
2.1 Knowledge Generation

지식 문장을 생성한다. 프롬프트는 1) 지시 사항, 2) 각 작업에 대해 고정된 몇 가지 데모, 3) 새 질문 으로 구성. 데모는 사람이 직접 작성하며, 각 데모는 과제 스타일의 질문과 이 질문에 답하는 데 도움이 되는 방법으로 작성한다. 주어진 과제에 대해 표 2의 형식을 사용하여 5개의 데모를 작성.
이때 위에 데모 예시들을 참고하여, 새로운 question이 들어올 경우 Knowlege를 M개 생성한다.
2.2 Knowledge Integration via Prompting
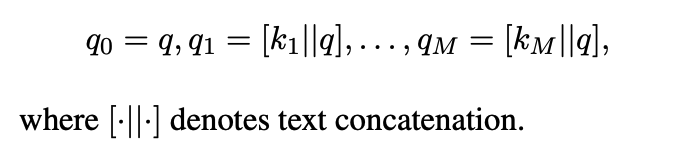
2.1에서 생성된 답변(k)와 질문(q)를 concat하여 Freeze언어모델에 입력한다.
여기서 생성, 예측한 q들중에서 가장 confidnece가 높은 것을 선택한다.
간단하게 말해서 여러번 추론해서 그중에서 가장 높은 예측값으로 나온 답변이 답이다를 복잡하게 아래 수식으로 표현함.

방법론 까지 읽고 흥미도가 급격하게 떨어졌다.. 이후는 중요한 부분만 간략하게 소개하고 넘어가고자 한다.
3. 실험

실험 표를 살펴보면, Ours가 RetrievalBased와 비슷한 점수를 보유한다. Retrieval Based는 웹에서 검색정보를 추가하여 만든 답변으로, 이와 유사한 답변의 성능을 보이는데서는 높은 점수를 주고 싶다.
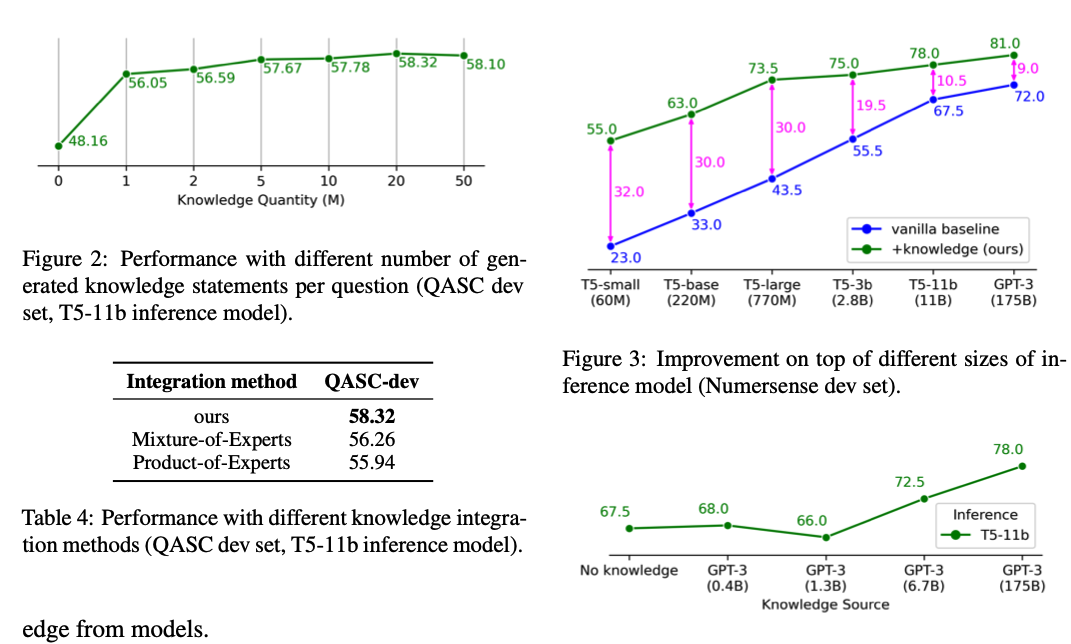
왼쪽 위 : 몇개의 질문을 생성했을 때 성능이 좋은지에 대해서 실험을 진행하였는데, 20번이 적절한 것으로 나왔다.
오른쪽 위 : (x축) 파라미터의 수가 적은 모델일 수록 이 논문에서 발휘하는 영향력이 크다 -> 아무리 작은 모델이라도 여러번 스택킹을 하면 좋은 결과물이 나옴. (백지장도 맞들면 낫다)
오른쪽 밑 : Knowledge Generation을 할 때에는 무조건 큰 모델이 좋다. (사람이 한 것과 비슷한 성능을 보일 수록 좋은 것으로 보임)