0. 요약
경쟁 모델들보다 훨씬 작은 크기인 새로운 대규모 언어 모델 phi-1을 소개한다.
- 모델 구성 : phi-1은 1.3B 파라미터로 구성된 Transformer 기반 모델
- 데이터 : 웹에서 수집한 "교과서 수준"의 데이터(60억 토큰) // GPT-3.5를 사용하여
- 훈련기간 : 8대의 A100에서 4일
이 비교적 작은 규모임에도 불구하고, phi-1은 HumanEval에서 50.6%의 pass@1 정확도 및 MBPP에서 55.5%의 결과를 달성
1. 개요
Transformer 아키텍처의 발견 이후에 놀라운 발전을 이루었지만, 여전히 한계가 있다. Transformer가 발견되고 엎치락 뒤치락 하는 연구들이 있었으나 공통점은 있어다. 컴퓨팅 자원이나 네트워크의 크기를 확장함에 따라 성능이 어느 정도 향상되는 현상이 있었다. 이러한 현상은 스케일링 법칙이라고 불린다. 이후 딥러닝 모델의 크기가 커지고 이러한 법칙의 변형의 발견은 성능의 급속한 향상을 이끌었다.
해당 연구는 스케일 외에 모델의 성능을 높이기 위한 방법인 데이터의 품질을 연구한다. 고품질 데이터가 더 좋은 성능을 이끌어내는 것은 오랫동안 알려져 왔다. Eldan과 Li의 작업에서 보여졌듯이 고품질 데이터의 영향은 스케일링 법칙을 극적으로 바꿀 수 있다. 따라서 더 간결한 훈련/모델로 대규모 모델의 성능에 비견될 수 있다. 이 연구에서 우리는 Eldan과 Li의 초기 시도를 넘어서 고품질 데이터가 대형 언어 모델의 최신 기술 수준을 개선할 수 있으며, 동시에 데이터셋 크기와 훈련 컴퓨팅을 크게 줄일 수 있음을 보여준다.
본 연구에서는 파이썬 코드를 작성하는 LLM에 집중하여 연구를 하였다.
- 1.3B 파라미터 모델인 phi-1을 약 8회의 패스 동안 70억 토큰 (약 500억의 총 토큰)을 사용하여 사전 훈련한 후, 2억 토큰 미만 데이터로 파인튜닝하는 것으로 스케일링 법칙을 깨며 고품질 데이터의 효능을 입증하였다.
- [CTJ+21, NPH+22, WKM+22, TGZ+23, MMJ+23, LGK+23, JWJ+23] 논문을 참고하여 GPT3.5에서 데이터 합성하여 모델 훈련에 사용
- 허나 이렇게 다른 모델로부터 생성된 데이터로 새로운 모델의 훈련에 사용하는 것은 narrower scope for the resulting 논란은 계속 되어 왔다.
- 본 연구에서는 narrow task에 집중 할 것으로, 데이터를 합성하여 사용한다.
2. 훈련 세부 사항 및 고품질 데이터의 중요성
표준 코드 데이터세트[KLA+22, LCC+22]는 광범위한 주제와 사용 사례를 포괄하는 크고 다양한 말뭉치를 형성하고 있다. 그러나 무작위 샘플을 수동으로 검사한 결과, 이러한 코드 조각 중 상당수가 코딩의 기초를 배우는 데 그다지 도움이 되지 않으며 몇 가지 단점을 가지고 있는 것으로 나타났다
- 많은 샘플은 독립적이지 않아 스니펫 외부에 있는 다른 모듈이나 파일에 의존하기 때문에 추가적인 맥락 없이는 이해하기 어렵다.
- 일반적인 예제는 의미 있는 계산을 포함하지 않고 상수 정의, 매개변수 설정 또는 GUI 요소 구성과 같은 사소하거나 단순화된 코드로 구성되어 있다.
- 알고리즘 로직이 포함된 샘플은 복잡하거나 제대로 문서화되지 않은 함수 안에 묻혀 있는 경우가 많아 따라하거나 배우기 어렵다.
- 예제가 특정 주제나 사용 사례에 치우쳐 있어 데이터 세트 전체에 코딩 개념과 기술이 불균형하게 분포되어 있다.
우리도 github들을 들여다보면, 클래스 상속의 상속의 상속... 사람도 이해하기 힘든 코드들이 많음
이와 같이 LLM에서도 이해하기 어려울 것
이러한 문제는 자연어를 코드로 매핑하는 신호의 품질을 떨어뜨리기 때문에 언어 모델의 성능에도 영향을 미친다는 가설을 세웠다.
이 연구에서는 이 문제를 직접적으로 해결하고 고품질 데이터를 의도적으로 선택하고 생성함으로써, 기존 접근 방식보다 훨씬 작은 모델과 적은 컴퓨팅으로 코드 생성 작업에서 최첨단 결과를 얻을 수 있음을 보여준다.
데이터는 아래와 같이 구성하였다.
1. LM Classifier를 사용해 얻은 필터링된 (코드-언어) 데이터 세트(약 60억 개의 토큰으로 구성됨)로, The Stack 및 StackOverflow의 일부
2. 10억 개 미만의 토큰으로 구성된 GPT-3.5로 생성된 파이썬 TextBook 합성 데이터 세트.
3. 약 1억 8천만 개의 토큰으로 구성된 파이썬 연습 문제 및 솔루션으로 구성된 소규모 합성 연습 문제 데이터 세트.
모든 데이터 셋은 합쳐도 7억개 미만의 토큰
훈련 방식
1. (1번 2번 데이터셋)Code-language, Textbook데이터를 활용해 훈련하여 phi-1-base를 훈련
2. (3번 데이터셋) CodeExercises 데이터 셋을 활용해 (1억 8천만 토큰) phi-1-base 모델을 미세 조정하여 phi-1을 얻음.
(CodeExercises 데이터 세트의 크기는 작지만, 이 데이터 세트를 사용한 미세 조정은 간단한 Python 함수를 생성하는 데 큰 개선이 있을 뿐만 아니라, 더 넓게는 phi-1-base 에서는 관찰되지 않는 많은 흥미로운 새로운 기능을 phi-1 모델에서 찾을 수 있음.)
2.1 Code DataSet을 Transformer기반 분류기로 필터링하기
중복을 제거한 Stack, StackOverflow 3,500만개 이상의 파일/샘플, 총 350억개 이상의 토큰을 포함한 Python 데이터를 사용. 이중에 일부 데이터인 10만개 정도의 데이터에 GPT-4를 사용해 품질에 대해 주석을 달았다. 코드가 주어지면 '기본 코딩 개념을 배우는 것이 목표인 학생에게 교육적 가치를 결정'하라라는 프롬프트를 작성하였다.(GPT-4는 지루하게 수작업으로 주석을 다는 부분을 생략하기 위해 사용)
주석이 발생한 데이터 셋을 - 코드를 생성하는 모델(Pretrained)를 사용하여 임베팅 출력을 뽑고, 이를 인풋으로 타겟을 품질을 예측하는 랜덤 포레스트 모델을 학습한다.
이렇게 필터링한 데이터를 사용하여 학습을 해도 모델 성능을 크게 향상 시킨다.
- 필터링 하지 않은 데이터 셋 : 350M 모델의 경우 HumanEval 성능은 12.19%
- 필터링된 데이터 셋 : HummanEval 17.68%
2.2 TextBook수준 데이터셋 합성하기
고품질 데이터 생성을 위해서는, 반복이 없으며 및 예제가 다양해야 한다.
- 다양성 : 코딩 개념, 기술 및 시나리오, 난이도, 복잡성, 스타일 등이 다양해야 한다.
다양성은 매우 중요한데, 한 문제를 푸는 과정에서 Overfit되지 않게 하며(암기 x), 일반화를 높이는데 매우 중요하다. 그러나 언어 모델에서 생성된 합성 데이터를 사용할 때 다양성을 확보하는 것은 쉬운 일이 아니다. 일반적인 방법으로 생성하면 매개변수 차이, 동일한 개념들이 들어가며 데이터를 생성 될 가능성이 매우 높다. 코드를 생성할 때 창의적이거나, 대안적인 방법을 생각하지 않을 가능성이 높다.
고정된 단어사전에서 랜덤으로 선택한 단어의의 일부를 프롬프트에 포함시키는 방법[EL23]에 영감을 받아, 프롬프트에 무작위성을 주입하는 방법을 고려했다.
The synthetic textbook dataset(1B)
이 데이터 세트는 10억 개 미만의 GPT-3.5 생성 Python 코드로 구성되어 있다. 추론 및 기본 알고리즘 기술을 주제로 다루며 TextBook의 내용을 더욱 세분화했다.

Code Exercise DataSet(180M)
파이썬 연습 문제와 솔루션으로 구성된 작은 생성된 연습 데이터 세트다. 이 데이터 세트의 목표는 자연어 명령어를 기반으로 함수를 완성하는 작업을 수행하는 것이다. 이 데이터 세트의 경우, 노이즈 제거 및 대체 평가를 수행하여 파인튜닝 중에 HumanEval 벤치마크와 유사한 문제가 나타나지 않도록 한다.

2.3 모델 아키텍쳐 및 훈련
- Transformer에서 Decoder Only Model 을 구성하였고, 어텐션의 구조는 FlashAttention을 사용하였다.
(플래시어텐션 외에도 성능과 효율성을 더욱 향상시킬 수 있는 FIM(Fill-In-the-Middle) [BJT+22] 또는
MQA(Multi-Query Attention) [RSR+20] [LAZ+23] 같은 다른 기법은 사용하지 않음.)
- CodeGen [NPH+22], PaLM [CND+22], GPT-NeoX [BBH+22]와 같은 모델과 같이 병렬 구성으로 MHA 및 MLP 레이어를 사용
- 1.3B 파라미터 phi-1 모델의 아키텍처 :
1) 24개의 레이어
2) Hidden Dim : 2048
3) MLP : 2048 -> 8192
4) NumberOfHead : 32(각각 64dim, 총 2048)
5) Positional Encoding : Rotery Positional Embedding
6) AdamW 옵티마이저, Learning Rate Scheduler(선형-워밍업-선형-감소), AttentionDropOut 0.1
7) fp16 트레이닝을 사용
- 토크나이저 : codegen-350M-mono 의 토크나이저를 사용함
- 데이터셋 : “⟨∣endoftext∣⟩” 토큰을 사용하여 데이터들을 연결하여 array형태로 만들고, 2048개의 token으로 슬라이스함.
딥스피드를 사용 8개의 Nvidia-A100 GPU에서 훈련. 사전 훈련된 기본 모델 phi-1-base는 훈련 4일, 파이-1을 얻기 위한 미세 조정에는 동일한 하드웨어에서 7시간이 추가로 소요.
훈련에 대한 좀더 디테일한 내용은 아래와 같다.
Pretraining. phi-1-base was trained on the CodeTextbook dataset (filtered code-language corpus and synthetic textbooks). We use effective batch size 1024 (including data parallelism and gradient accumulation), maximum learning rate 1e-3 with warmup over 750 steps, and weight decay 0.1, for a total of 36,000 steps. We use the checkpoint at 24,000 steps as our phi-1-base – this is equivalent to ∼ 8 epochs on our CodeTextbook dataset for a total of little over 50B total training tokens. Despite the small size and computation, this model already achieves a 29% accuracy on HumanEval.
Finetuning. phi-1 is obtained by finetuning phi-1-base on the CodeExercises dataset. For finetuning, we use the same setup as pretraining, but different hyperparameters: we use effective batchsize of 256, maximum learning rate 1e-4 with 50 steps of warmup, and weight decay 0.01. We train for total of 6,000 steps and pick the best checkpoint (saved every 1000 steps).
3. CodeExercise에서 파인튜닝한 후 모델 능력의 상승

위에서 보듯, 가장 큰 개선은 CodeExercises 데이터셋(<200M 토큰)에 대한 파인튜닝에서 발생했다. CodeExercises는 기본적인 파이썬 라이브러리만 사용하는 짧은 파이썬 작업으로 구성되어 있으며, 특이한 점은 파인튜닝 이후 모델이 파인튜닝 데이터셋에 포함되지 않은 작업을 실행하는 데 상당한 개선이 있었다. 특히 복잡한 알고리즘 작업을 처리하고 외부 라이브러리를 사용하는 것에 개선이 있었다. 파인튜닝 과정에서 사전 훈련 중에 습득한 지식을 재구성하고 정리하는 데 기여했음을 시사한다.
3.1 파인튜닝이 모델의 이해력을 향상시킵니다.
파인튜닝 이후 모델이 지시 사항을 훨씬 더 잘 이해하고 준수함을 관찰했다. 특히, phi-1-base가 프롬프트의 논리적 관계에 어려움을 겪는 반면, phi-1은 질문을 해석하고 정확한 답변을 생성할 수 있다는 것을 볼 수 있다. 아래의 문제에서는 답은 틀렸으나, 350M phi-1-small 모델도 문제의 일정 부분을 이해하는 것 처럼 보인다.

3.2 파인튜닝은 모델의 외부 라이브러리 사용 능력을 향상시킵니다.
CodeExercises에서의 파인튜닝과정에서는 Pygame, Tkinter와 같은 패키지를 사용하는 데이터가 없더라도 외부 라이브러리를 사용하는 모습을 보여준다. 이는 우리의 파인튜닝이 목표로 한 작업뿐만 아니라 관련 없는 작업도 사전 훈련에서 배웠던 지식들을 더 쉽게 추출할 수 있도록 만든다는 것을 시사한다.

- phi-1 : 프롬프트에 따라 지시된 대로 PyGame 함수를 올바르게 적용하여 공을 업데이트하고 그린다.
- phi-1-base : 문법적으로는 올바른 함수 호출을 생성하지만 목적과 다른 코드를 생성, 적절한 API 호출을 사용하는 능력을 일부 보여주지만 작업의 논리를 따르지 못함
- phi-1-small : 문법적으로는 올바른 함수 호출을 생성, 파인튜닝 후의 phi-1-small은 논리를 이해하지만 올바른 함수 호출을 학습할만한 충분한 weight가 없음.
Tkinter 예시
- phi-1 : GUI 및 모든 함수를 옳바르게 구현
- phi-1-base, phi-1-small : 옳바른 Tkinter API를 사용하지 못하고, 의미 없는 함수 호출함.
4. 일반적이지 않은 상황에서의 평가
phi-1이 너무 뛰어난 성과를 보여, CodeExercise데이터셋을 만드는 과정에서 문제유출(암기)가 되었을 수 도 있다는 생각을 한 것같다. 따라서 이 우려를 해결하기 위해 새로운 Evaluation Problem을 만들었고, HumanEval문제와 동일한 형태로 바꾸어 실험하였다.
아래는 문제의 예시이다

Code를 생성하는 모델의 어려운 점은, 종종 결과물이 Binary형태이다. 특히 모델의 중간부분은 아주 조금 틀렸으나 답이 틀렸을 수도있고, 답은 맞았으나 중간 과정은 완전 틀렸을 수도 있다. 코딩테스트와 비슷하게, 결과물을 비교하고, 중간 논리가 얼마나 잘 맞나 점수를 메기는게 타장해 보인다. 해당 연구에서는 GPT4를 정답으로 삼아 평가를 진행한다[EL23]. 이렇게 할 경우 두가지 장점이 있다. 1) GPT4를 평가자로 사용하여, 평가 모델의 코딩 능력에 대해 세밀하고 의미있는 평가를 얻을 수 있다. 2) 전통적인 테스트의 필요성을 제거한다.

만든 50개의 데이셋에 대해서 평가 결과 HummanEval은 phi-1-small만 되더라도 기존의 모델들의 성능을 앞선다.
5. CodeExercise데이터 수정을 통해 FineTuning의 효과 검증
CodeExercises에서 성능이 크게 향상 된 것을 보았다. 허나 진짜 향상 된 것인지 의심이 되었는지, CodeExercises 데이터 셋에서 HumanEval과 유사한 데이터를 제공하여 재학습을 하였다. 재학습을 하였음에도 불구하고 여전히 HumanEval에서 강력한 성능을 관찰하였다. 특히 CodeExercises데이터 셋의 40%이상을 가공하였는데도 phi-1이 여전히 StarCoder보다 우수한 성능을 보인다.
5.1 N-gram으로 HumanEval과 CodeExercise 유사성 비교
HumanEval질문과 CodeExercise문제 사이에서 n-gram중복을 계산하고, 중복된 몇개의 데이터셋을 발견 할 수 있었다.

5.2 Embedding 및 Syntax-based 유사성 비교 분석
n-gram분석은 유사한 부분을 찾는데 정교하지 않다. 대신 임베딩과 구문 기반 거리 조합을 사용하여 유사성을 비교한다.
- 임베딩 거리 : 코드 스니펫의 임베딩을 계산하여 L2거리를 계산한다. 여기서 임베딩은 CodeGen-Mono 350M에서 계산된다
- ASTs(Abstract Syntax Trees) : 구문 기반 거리 조합에서는 변수, 함수 등
임베딩 거리를 사용하여 두 쌍의 코드가 유사한지 판별하는데 성공하였다. (Doctring, 함수 클래스 이름, 코드 구조 등).
특정 값을 선정하고 Embedding Distance에서 거른뒤, AST를 τ를 변화시키면서 Sim, Non-Sim으로 구분하여 실험을 진행한다.
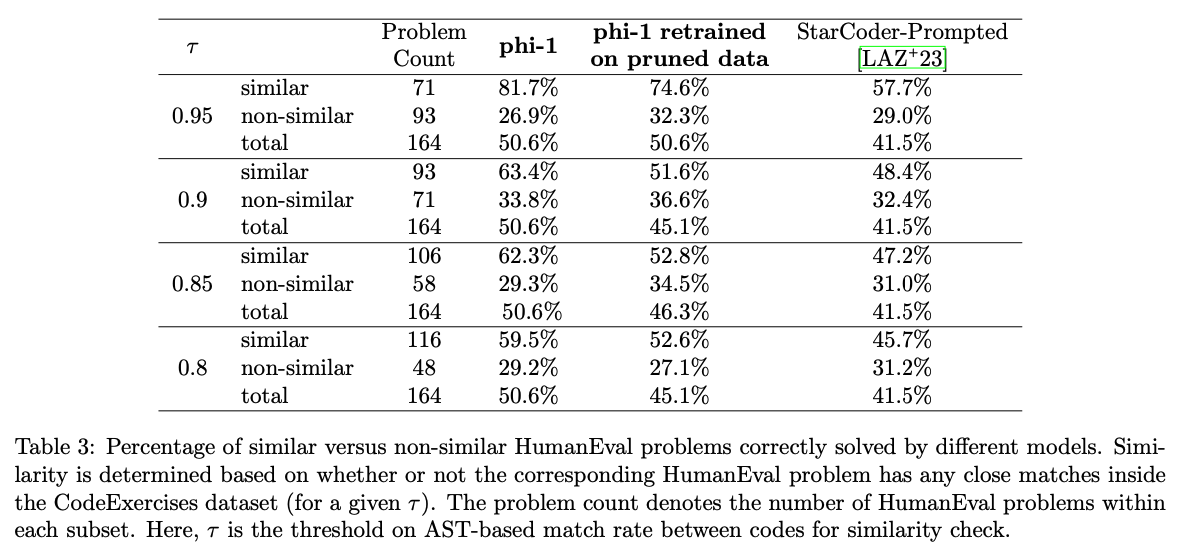
유사한 데이터셋을 가공한 후에 훈련한 모델인 phi-1에서도 15.5B 파라미터를 갖춘 StarCoder-prompted보다 우수하다. 이는 phi-1의 성능이 데이터셋의 오염(암기)로 인한 것이 아니라는 것을 확인할 수 있다. 허나 비슷하지 않은 데이터로 학습한 phi-1의 성능이 낮아짐을 볼 수 있음.
6. 정리하며
높은 품질의 데이터 셋의 중요성을 입중하였음. 다른 모델 대비 10배, 데이터셋 크기에서 100배나 작은데 불구함에도 최고 수준의 성능을 달성함. 다만 큰 모델에 비해 몇 가지 한계점이 있다.
1. phi-1은 Python 코딩에 특화되어 다중 언어 모델과 비교했을 때 다용도성이 부족하다.
2. Phi-1은 특정 API를 사용하거나 드물게 사용되는 패키지를 사용하는 등 큰모델에 비해 도메인별 지식이 부족하다.
3. 훈련 데이터은 구조화된 데이터셋이 많아 언어 및 스타일의 다양성을 배울 수 없엇을 것이라, 프롬프트의 문접적 실수가 있을 경우 성능이 상당히 저하된다.
이러한 한계들을 극복하는데 본직적으로 불가능하다 생각하지 않지만, 이를 극복하기 위해 어떤 스케일링(모델, 혹은 데이터셋)이 필요한지는 분명하지 않다.
GPT-4를 사용하여 합성 데이터를 생성할 경우, 데이터의 오류율이 높다는 것을 발견하였다. 하지만 이러한 오류울에도 불구하고 높은 성능을 달성할 수 있다(AZL23에서도 관찰됨)
언어 모델이 더 좋은 방향으로 발전하기 위해서는 고품질의 데이터를 생성하기 위한 방법론을 개발하는 것이다. 그러나 고품질 데이터를 생성하는 것은 쉬운 작업이 아니며 몇가지 도전 과제가 있다.
1) 모델이 학습하기 원하는 모든 관련 내용과 개념을 데이터셋에서 균형있고 대표적인 방식으로 커버하고 있는지 확인
2) 데이터셋이 다양성을 확보하고, 반복성이 없는지 보장하는 것 -> 오버핏, 메모라이제이션 문제
데이터 생성 과정에서 무작위성과 창의성을 주입하는 방법을 찾는 것이 필요하다. 또한 데이터 셋을 만들고나서 데이터의 다양성과 중복성을 측정하고 평가하는 좋은 방법론이 부족하다. 예를들어 코딩 연습 문제가 있는 데이터셋이 있다면, 각 문제의 다양한 변형이 얼마나 있는지와 이들이 데이터셋 전체에 어떻게 분포되어 있는지를 결정하는 것은 어렵다.
3) 데이터를 선별하는데 언어모델이 사용될 것인데, 평가하는 언어모델의 Bias가 문제가 될수도 있다.(인종, 종교, 성별 등)
https://arxiv.org/abs/2306.11644
Textbooks Are All You Need
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the w
arxiv.org