3.2 각 질문에 대해 핵심 추론 단계 v = {v₁, v₂, ...}를 미리 추출
이 논문에서 사용한 데이터셋은 Mulberry-260k인데, 이미 CoT경로가 포함된 데이터 셋임. 여기서 꼭 필요한 중간단계를 추출하는 것임.
3.2 M개의 궤적을 얻고 추론 궤적을 평가하고 보상함. 이때 두가지 보상을 줌.
- StepRAR: 단계별 추론 정확도
- StepRVR: 추론 타당성 보상
Abstract
- 현재 MLLM 추론 향상 방법의 한계
- 고품질 chain-of-thought 데이터에 대한 supervised fine-tuning 중심
- 모델이 성공적인 추론 경로만 모방하고 잘못된 추론 경로를 이해하지 못함
- 제안하는 해결책: StepGRPO
- MLLMs가 자체적으로 추론 능력을 향상시킬 수 있는 online reinforcement learning 프레임워크
- 단계별 보상을 통해, 세세하고도 밀도 높은 학습 가능
- 두 가지 핵심 보상 메커니즘
- StepRAR(Step-wise Reasoning Accuracy Reward)
- 필요한 중간 추론 단계 포함 여부 평가
- Soft key-step matching 기술 활용
- StepRVR(Step-wise Reasoning Validity Reward)
- 추론 과정의 구조적 완성도와 논리적 일관성 평가
- StepRAR(Step-wise Reasoning Accuracy Reward)
Introduction
- 추론 개선 최근 연구 접근법
- 강력한 모델(GPT4 등)로 생성한 CoT 데이터로 supervised fine-tuning
- 예: Mulberry의 CoMCTS(여러 모델이 협력하여 추론 경로 탐색)
- 한계: 성공적인 추론 경로만 모방하고 실패 경로는 무시
- 강화학습을 통한 새로운 접근법
- NLP 분야에서 Deepseek-R1, Kimi-K1.5 등이 자체 탐색 능력 보여줌
- 핵심: 보상 모델 없는 online reinforcement learning(GRPO 등)
- 문제점: MLLM에 직접 적용 시 sparse reward 문제 발생
- 특히 작은 모델들은 long-chain 추론에 제한된 능력
- 대부분 추론 경로가 낮은 보상 → 탐색 효율성 감소, 학습 불안정
제안: StepGRPO 프레임워크
- Dense step-wise 추론 보상 도입으로 sparse reward 문제 해결
- 두 가지 규칙 기반 추론 보상 메커니즘 포함:
- StepRAR: 핵심 중간 추론 단계 포함 여부 평가
- StepRVR: 추론 과정의 구조와 논리적 일관성 평가
- 보상 모델 없이도 정보성 높은 피드백 제공 가능
StepGRPO의 주요 장점
- 효과성: 전체 추론 과정에 걸쳐 세밀한 보상 제공
- 효율성: 추가 보상 모델 없이 규칙 기반으로 단계별 보상 제공
2. Related Work
2.1 Multimodal Large Language Model
- MLLMs의 발전
- Vision-language 이해 분야에서 놀라운 성과
- 초기: 텍스트 프롬프트와 이미지 기반 텍스트 생성 중심
- 최근 발전:
- 다양한 입출력 모달리티(비디오, 오디오, 포인트 클라우드) 지원
- 의료 이미지, 문서 분석 등 도메인 특화 작업 적응
2.2 MLLM Reasoning
- 기존 MLLM 추론 향상 방법
- 강력한 모델(GPT-4)로 CoT 데이터 생성 후 SFT 수행
- 본 연구의 차별점: 자체 탐색을 통한 추론 능력 향상 목표
2.3 Reinforcement Learning
- LLM과 강화학습
- RLHF: 인간 선호도 데이터로 모델 fine-tuning
- PPO, DPO 등 알고리즘 활용해 응답 품질 향상
- 추론 능력 향상을 위한 강화학습
- 수학 문제 해결 등에 점점 더 많이 적용
- 접근법:
- ReST-MCTS*: 각 추론 단계 정확성 평가 위한 process reward model 훈련
- 최근 발견: 단순한 outcome-level 규칙 기반 보상도 효과적
- DeepSeek-R1: GRPO와 outcome-level 보상으로 LLM 추론 능력 향상
- 본 연구: MLLMs의 sparse reward 문제 해결 위한 StepGRPO 제안
3. Method
3.1 Task Formulation
- 사전훈련 모델: $π_θ$
- 질문: Q(이미지, 텍스트 지시 포험)
- 모델의 답변: c(추론과정을 포함)
- c = $(a_1, a_2, ..., a_t)$
- 새로운 상태 $s_{t+1}$: 현 상태 $s_t$ 및 추론 $a_t$로 새로운 상태가 생성됨.
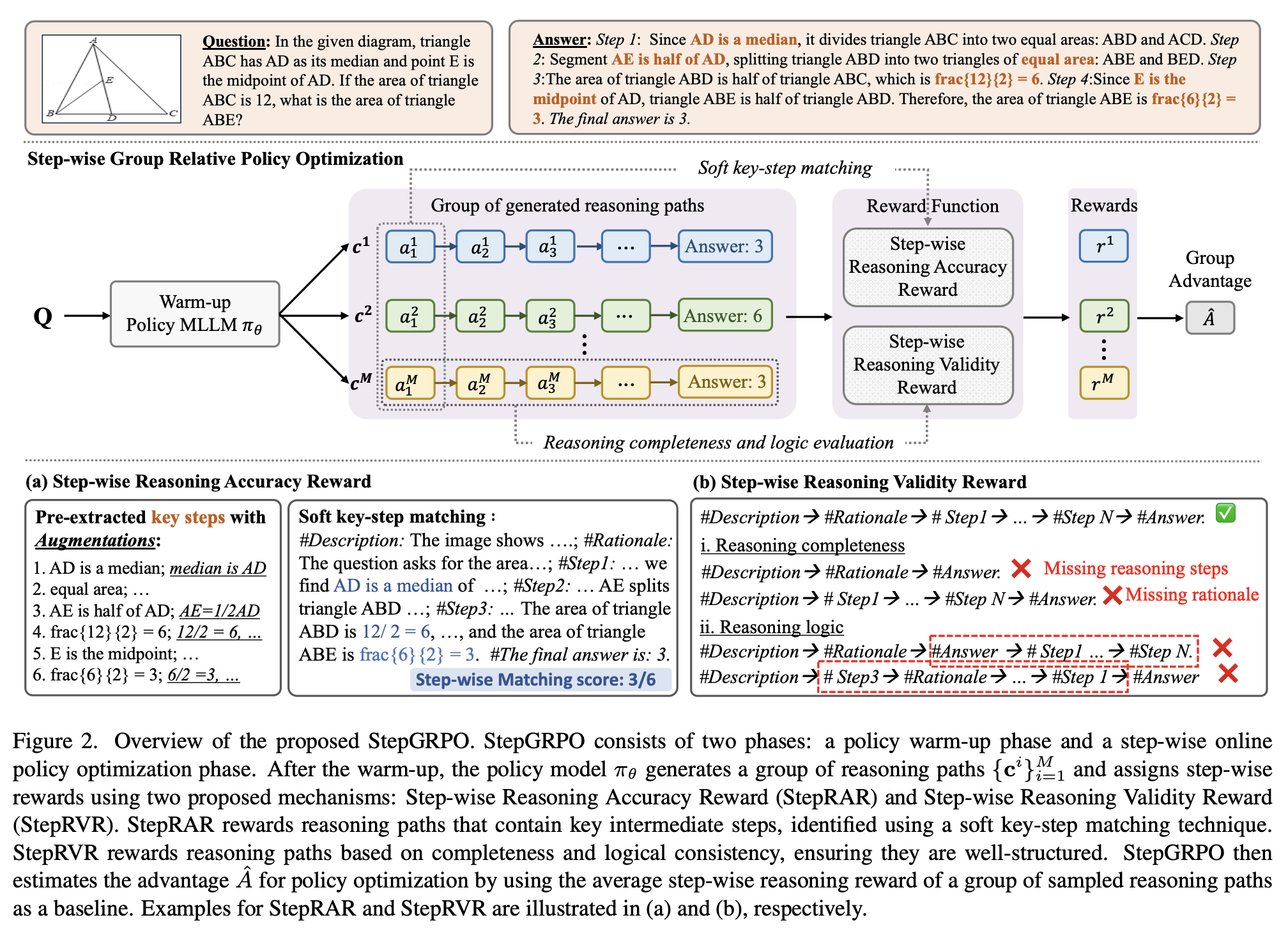
- 보상: $r(s_t, a_t, s_{t+1}$
3.2 Step-wise Group Relative Policy Optimization
두 단계로 구성: Policy warm-up, Step-wise online policy optimization
- Policy Warm-up: LLM에 기본적인 추론 능력을 부여. 강화학습 전에 적절한 추론을 생성할 수 있도록 준비
- Chain-of-Thought(CoT) 추론 경로가 있는 멀티모달 데이터셋 $D_s$를 사용하여 파인튜닝함.
- $D_s = {Q^n, τ^n}^N_{n=1}$
- Q: Question
- τ: reasoning path
- $L_{warm_up} = -E_{τ~D_s}[\sum log(π_θ(a_t|s_t))]$: SFT진행
- Step-wise Online Policy Optimization: 온라인 강화학습을 통해 추론 능력을 자체적으로 향상시킬 수 있게 함. 단계별 추론 보상을 통해 sparse reward 이슈를 완화.
- (그림2) 데이터마다, 질문에 대해 여러번의 rollout을 통해 M개의 추론 궤적{${C&i\}^M_{i=1}$}을 생성함. 이때 $C^i = (a^i_1, a^i_2, ..., a^i_T)$임.
- M개의 궤적을 얻고 추론 궤적을 평가하고 보상함. 이때 두가지 보상을 줌.
- StepRAR: 단계별 추론 정확도
- StepRVR: 추론 타당성 보상
- Step-wise reasoning accuracy reward(StepRAR): 추론 경로가 올바른 중간 추론 단계를 포함하는지 평가
- 각 질문에 대해 핵심 추론 단계 v = {v₁, v₂, ...}를 미리 추출.(GPT-4를 사용하여 추출함)
이 논문에서 사용한 데이터셋은 Mulberry-260k인데, 이미 CoT경로가 포함된 데이터 셋임. 여기서 꼭 필요한 중간단계를 추출하는 것임.- 추출된 결과에서 중복 정보를 제거하고, 핵심 단어만 유지함. 또 각 추출된 정보를 등가 형식으로 증강해, 같은 formula를 측정할 수 있음. 예) \frac{6}{3} = 2"는 "6/3 = 2" 또는 "6 나누기 3은 2와 같다"로 증강
- match score: $k^i = |v_{match}|/|v|$
여기서 v는 extracted 추론 단계이고, 생성된 것 중에 v match된 것임. - 최종 Reward는 아래와 같이 표현됨
여기서 Y는 CoT추론에서 추출한 정답임.
-> 추론 과정을 맞춤으로서, 모델이 무작위로 답을 추측하는 대신 추론 과정을 학습하도록 보장함.
맨위: 정답인 경우, 중간: 오답이지만 답변이 있는 경우, 마지막: 답변이 없는 경우
- 각 질문에 대해 핵심 추론 단계 v = {v₁, v₂, ...}를 미리 추출.(GPT-4를 사용하여 추출함)
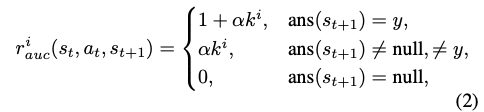
- Step-wise reasoning validity reward (StepRVR): 추론 경로가 구조화되고 일관되게 생성되도록 함.
-> 단계별로 타당성을 측정. 두가지 측면 $δ^c(reasoning completeness)$ and $δ^l (reasoning logic)$- $δ^c(reasoning completeness)$: 3가지 측정
- 배경 분석: 이미지 설명, 원리 분석
- 단계별 추론과정
- 답변
- $δ^l (reasoning logic)$: 논리적인 흐름을 따르는지 확인
-> 예) 배경 분석은 해결 단계 전에 나와야함. - 최종 reward는 아래와 같이 정의함.
완전성과 논리성 모두 만족하면 점수를 받음.
- $δ^c(reasoning completeness)$: 3가지 측정

- Optimization with the step-wise rewards:
- 전체 보상: $r^i = r^i_{auc} + r^i_{val}$ 계산
- 모든 Reasoning path M에 대해서 계산: {$r^1, r^2, ..., r^M$}
- Normalize: 식(4)
같은 그룹에 있는 다른 reasoning 궤적과 비교했을 떄 얼마나 좋고 나쁜지 비교를 하기위함. - 최종 Loss: 식(5)
- Ds에 데이터에 대해서, 궤적들(M)을 다 구한뒤 $A^i$를 계산함.
- (논문에서는 밝히지 않았으나) 분자는 계속 업데이트 되는 모델이고, 분모는 바로 전 epoch(or iteration)의 모델을 가져와서 확률값을 계산함. 이렇게 함으로써 모델이 스스로 발전하게 만들고, 너무 많이 변하는 것을 방지함.
- KL Div: DeepSeekMath에 나온 것과 같은 함수
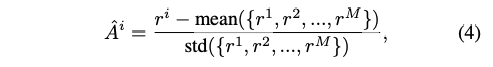
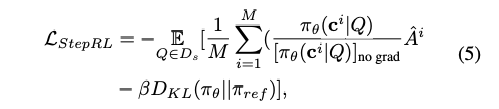
4. Experiment
4.1 Datasets
- Policy warm-up: Mulberry-260k를 supervised fine-tuning에 활용
- Step-wise online policy optimization: Mulberry-260k에서 무작위로 추출한 10K 데이터 사용
- 평가 벤치마크: 8개의 다양한 멀티모달 벤치마크 활용
- MathVista, MMStar, Math-Vision, ChartQA, DynaMath, HallusionBench, MathVerse, MME
- 수학적 추론, 차트 이해, 시각적 환각, 일반 시각적 이해 등 다양한 작업 포함
4.2 Implementation Details
- 기본 모델: Qwen2-VL-2B와 Qwen2-VL-7B 활용
- Policy warm-up 설정:
- 배치 크기: 128
- 학습률: Qwen2-VL-2B는 1e-5, Qwen2-VL-7B는 5e-6
- Step-wise online policy optimization 설정:
- 질문당 rollout 수(M): 4
- 샘플링 온도: 1.2 (다양한 추론 경로 생성 촉진)
- 최대 시퀀스 길이(L): 1024
- 모델 학습률: 1e-6
- 배치 크기: 4
- 매치 점수 계수(α): 0.1
- KL 발산 계수(β): 0.04
- 하드웨어: 4개의 H100-80GB GPU
4.3 Main Experimental Results
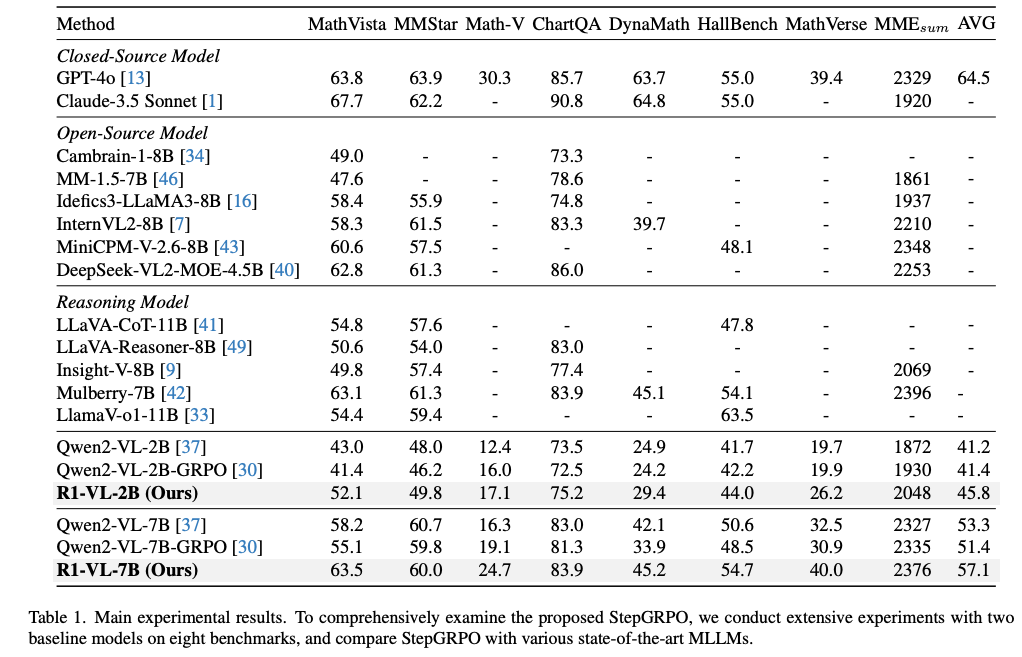
- 기준 모델과의 비교:
- GRPO를 기준 모델에 직접 적용 시 sparse reward 문제로 성능 저하 발생
- R1-VL은 기준 모델 대비 큰 성능 향상 달성 (Qwen2-VL-2B: +4.6%, Qwen2-VL-7B: +3.8%)
- StepGRPO의 step-wise 보상이 각 추론 단계에서 풍부한 감독 제공하여 sparse reward 문제 완화
- 최첨단 추론 MLLM과의 비교:
- 대부분의 벤치마크, 특히 수학적 추론 작업에서 우수한 성능 달성
- R1-VL-7B는 MathVista에서 Mulberry-7B보다 0.6%, LlamaV-o1-11B보다 9.3% 높은 성능
- 소형 모델인 R1-VL-2B도 대형 모델(LLaVA-Reasoner-8B, LLaVA-CoT-11B)보다 높은 성능 달성
- 일반 MLLM과의 비교:
- 대부분의 오픈 소스 MLLM보다 우수한 성능 달성
- 비공개 모델(GPT-4o)과 유사한 수준의 성능 달성 (MathVista: R1-VL-7B 63.7 vs GPT-4o 63.8)
4.4 Albation Study
- 주요 구성 요소 영향 분석 (Qwen2-VL-7B, MathVista 기준):
- Warm-up 단계: 기준 모델을 61.2%로 향상시켜 강화 학습 전 기본적인 추론 지식 학습 가능
- StepRAR/StepRVR: 각각 독립적으로도 warm-up 모델보다 큰 성능 향상 제공
- StepRAR + StepRVR: 최고 성능(63.7%) 달성, 중간 단계 정확성과 논리적 구조 모두 강화 효과
4.5 Discussion
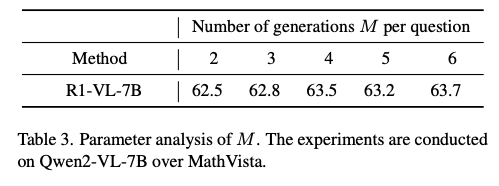
- Parameter analysis. (table 3)
- 그룹 내 생성 수(M)의 영향:
- 더 큰 M값이 일반적으로 더 높은 성능으로 이어짐
- 이유: 더 많은 샘플링으로 더 안정적이고 정확한 기준 보상 추정 가능
- 작은 M값은 기준 추정에 높은 분산 초래, 최적화 과정 신뢰성 저하
- 계산 비용과 성능 균형을 위해 M=4를 기본값으로 설정
- 그룹 내 생성 수(M)의 영향:
- Effectiveness of the step-wise reward. (table 4)
- 세 가지 설정 비교: Warm-up only, Warm-up + Outcome-level Reward, Warm-up + Step-wise Reward (제안 방법)
- 결과:
- Outcome-level 보상과 Step-wise 보상 모두 Warm-up 모델 성능 향상
- Step-wise 보상이 가장 우수한
- 이유: 더 세밀한 감독 제공 및 sparse reward 문제 완화

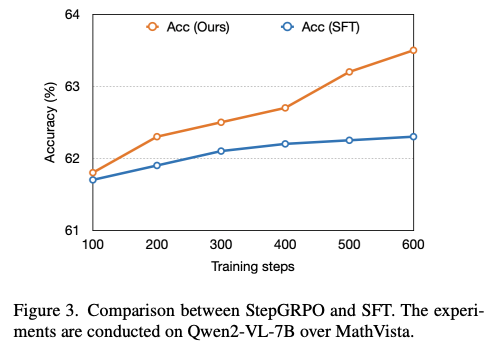
- Comparison to supervised fine-tuning (SFT). (figure 3)
- 실험 설정: Warm-up 이후 모델 기준, 동일한 훈련 단계 수 비교
- 결과: StepGRPO가 모든 훈련 단계에서 일관되게 SFT 성능 상회
- 이유:
- StepGRPO는 자기 탐색과 보상 기반 최적화로 추론 능력 향상
- Step-wise 보상이 SFT보다 더 풍부하고 유익한 감독 제공
- Quanlitative comparison
5. Conclusion