논문을 읽었으나, 구조가 복잡하여, 코드를 살펴봐야 할 것
https://github.com/cpacker/MemGPT
GitHub - cpacker/MemGPT: Letta (fka MemGPT) is a framework for creating stateful LLM services.
Letta (fka MemGPT) is a framework for creating stateful LLM services. - cpacker/MemGPT
github.com
Abstract
- 제한된 context window로 인해 긴 대화나 문서 분석과 같은 작업에서는 퍼포먼스가 약함
- context window 범위를 넘어서는 context를 활용하기 위해, virtual context management 기술을 제안
*(운영체제가 physical memory와 disk 사이의 paging을 통해 확장된 virtual memory를 제공하는 것과 유사함.) - MemGPT(MemoryGPT) : 제한된 context window 내에서 효과적으로 확장된 context를 제공하기 위해 서로 다른 storage tier를 관리하는 시스템
1. 문서 분석: MemGPT는 기존 LLM의 context window를 크게 초과하는 대규모 문서를 분석할 수 있다.
2. 다중 세션 채팅: MemGPT는 대화형 에이전트가 사용자와의 장기적인 상호작용을 통해 기억하고, 반영하고, 동적으로 발전한다.
1. Introduction
- 현 LLM은 다방면에서 잘하고 있음
허나, 제한된 context window로 인해 적용 가능성을 크게 제한한다.
최근 연구에 따르면 long-context 모델이 context를 효과적으로 활용하는 데 어려움을 겪는다는 것을 보여준다. - 이 논문에서, 고정 context를 사용하며 무한한 context를 사용하는 방법을 연구함.
- LLM 에이전트의 function calling을 활용하여 virtual context management를 위한 LLM 시스템인 MemGPT를 설계
- Function call을 통해 LLM 에이전트는 외부 데이터 소스를 읽고, 쓰고, 자체 context를 수정하고, 사용자에게 응답을 제공하는 시점을 선택한다.
- 이러한 기능을 통해 context window("main memory"에 해당)과 외부 저장소 사이에서 효과적으로 정보를 "paging" 한다.
- function call은 context 관리, 응답 생성, 사용자 상호작용 간의 제어 흐름을 관리하는 데 활용
- 이를 통해 에이전트가 단일 작업에 대해 context에 있는 내용을 반복적으로 수정하여 제한된 context를 더 효과적으로 활용
- function calling과 이벤트 기반 제어 흐름의 메모리 계층을 결합하여 사용하여 MemGPT는 유한한 context window를 가진 LLM을 사용해 무제한의 context를 처리한다
- 평가 :
- 문서 분석: 표준 텍스트 파일의 길이가 현대 LLM의 입력 용량을 빠르게 초과할 수 있는 영역
- 대화형 에이전트: 제한된 대화 window로 인해 LLM이 확장된 대화 중에 context 인식, 페르소나 일관성, 장기 기억이 부족한 영역
- 두 설정 모두에서 MemGPT는 유한한 context의 제한을 극복하여 기존 LLM 기반 접근 방식보다 더 나은 성능을 보여줌
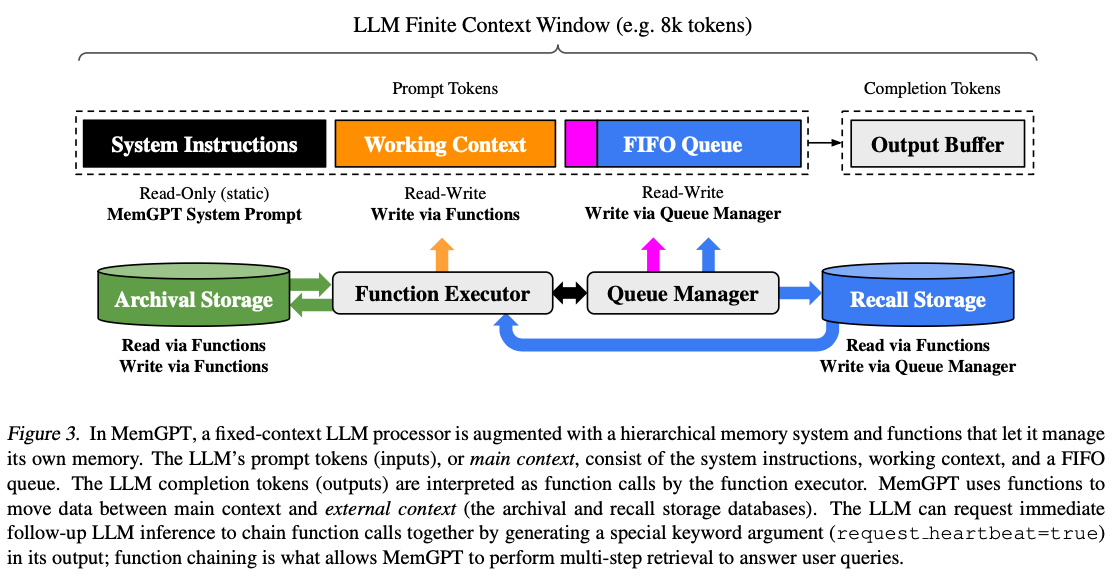
2. MemGPT(MemoryGPT)
두 가지 주요 메모리 유형을 구분 :
- Main context (main memory/physical memory/RAM과 유사)
- LLM prompt tokens로 구성 : main contedt에 있는 모든 것은 In-context로 간주되어, 추론하는 동안 LLM processor에 의해 접근이 가능함. - External context (disk memory/disk storage와 유사)
- 외부에 저장된 모든 데이터를 의미함. out-of-context 데이터는 inference중에 LLM processor에 전달되기 위해서는, 반드시 main context로 데이터를 이동 시켜야 한다.
MemGPT는 LLM processor가 사용자 개입 없이 자체 메모리를 관리할 수 있도록 function call을 제공한다.
2.1 Main Context (Prompt Tokens)
(Figure 3의 상단 부분)MemGPT의 prompt tokens는 세 개의 연속된 섹션으로 구성되어 있다.
- System instructions
- 읽기 전용(정적), (control flow / 다른 메모리 레벨의 사용법 / MemGPT 함수 사용법 - out-of-context데이터를 검색하는 방법)을 포함한다. - Working context
- 고정된 크기의 읽기/쓰기 블록으로, 비정형 텍스트를 저장하는 용도로 사용하며, MemGPT의 function call을 통해서 쓰기 가능하다. system instruction과 달리 수정이 가능하다
- 핵심 사실 저장, 사용자 선호도 저장, 에이전트의 페르소나 관련 중요 정보 저장, 대화 맥락에서 자주 참조되는 중요 정보 유지 등에 사용된다 - FIFO Queue
- 롤링 히스토리 형태로 데이터를 저장한다. 새로운 메시지가 들어오면 가장 오래된 메시지부터 제거하며, 동적으로 크기가 변한다.
- 에이전트와 사용자 간의 대화 메시지를 저장하고, 시스템 미시지, function call 입력 출력 등을 저장한다.
- Warning Token Count( context window 70% 도달 시)
- 중요 정보를 working context, archival storage로 정보를 이동시킴 - Flush token count (context window 100% 도달 시)
- Context window 50% 제거
- 제거된 메시지는 recall storage에 저장
- Warning Token Count( context window 70% 도달 시)
- 정리하자면, system instruction은 절대 바뀌지 않을 정보들이 저장 (
AI는 인간을 헤칠수 없어 와 같은 절대적 룰들)
working context는 장기 기억이 필요한 중요 정보를 저장 - long memory
fifo queue는 현재 진행중인 대화의 흐름 관리 - short memory
2.2 Queue Manager(storage, overflow제어, flush token count)
recall storage와 FIFO queue의 메시지를 관리함.(Figure 3의 하단 부분, 파란 화살표)
- 시스템이 새 메시지를 받으면 queue manager는 :
- 수신 메시지를 FIFO queue에 추가
- Prompt Tokens에 연결
- LLM output을 생성하기 위해 LLM inference를 실행
메시지 예시 :
- User: "What do you remember about my birthday?"
- System: "Memory pressure warning: Context window at 70% capacity",
- Event: "User completed document upload: analysis_doc.pdf"
- Function Result: "Retrieved 3 relevant passages from archive"
recall storage :
- LLM의 context window 외부에 위치한 저장소
- 메시지와 대화 히스토리를 무기한 저장
- 필요할 때 데이터를 검색하여 main context로 가져올 수 있음
- Queue Manager는 수신 메시지 및 LLM출력물을 모두 recall storage에 기록함.
- MemGPT가 function call을 통해 Recall Storage에서 메시지 검색 요청
- Queue Manager가 검색된 메시지를 FIFO Queue 끝에 추가
- 추가된 메시지는 LLM의 Context Window에서 접근 가능
-> 위 과정은 dynamic RAG와 비슷함.
[Recall Storage] ---(Function Call)---> [Queue Manager] ---(추가)---> [FIFO Queue] ---> [Context Window]
1. 초기 대화:
사용자: "내 생일은 3월 15일이야"
시스템: [메시지를 Recall Storage에 저장]
2. 나중의 대화:
사용자: "내 생일이 언제였지?"
시스템: [Function Call로 Recall Storage 검색] (vector search)(cos sim) (3.1에서 설명할 예정)
시스템: [관련 메시지를 FIFO Queue에 추가]
시스템: "당신의 생일은 3월 15일입니다."
- Queue Manger는 queue eviction policy를 통해 context overflow 제어
- 목적 : context overflow 방지, 중요 정보 보존
- 작동 : Prompt token이 70% 정도 차지하게 되면, 작동함.
FIFO Queue (현재 상태)
-> 메모리 사용량 70% 초과 감지
-> 'Memory Pressure' 경고 메시지 삽입
-> LLM에게 중요 정보 저장 지시
- Queue Manager는 flush token count를 통해 context window 제어
- Prompt tokens가 context window 100% 초과시
- 추가적인 context window가 필요함.
- 작동 : Context Window의 50%에 해당하는 메시지를 큐에서 제거
-> 제거되는 텍스트는 recall storage로 이동
-> 제거되는 텍스트는 요약하여 FIFO Queue의 첫 번째 위치에 저장
- queue eviction policy와 flush token count는 비슷한것 같은데?
- eviction : 예방 단계
- Flush : 강제 정리 단계
2.3 Function Executor

기본 역할
- function call을 통해 main context와 external contxt사이 데이터 이동을 조율함.
- LLM processor가 생성한 function call을 처리
- 대화 기록이 너무 길어질 때(그림 1에서 보여지는 것처럼) context 간에 항목을 이동하고, 현재의 목표와 책임에 대한 이해를 더 잘 반영하도록 main context를 수정
메모리 관리 자율성
- Self-directed 메모리 편집과 검색
- 대화 기록이 길어질 때 context 간 데이터 이동
- 현재 목표에 맞게 main context 수정
구현 방식
- system instructions에 명시적 지침 포함
1. 메모리 계층에 대한 설명
2. Function schema(메모리 접근 및 수정용 함수 정의)
1. 첫 시도: Main context에 새 데이터 추가 시도
2. 에러 발생: "Context 용량 초과"
3. 피드백 수신: 용량 초과 에러 확인
4. 적응: 다음 시도에서는 오래된 데이터를 먼저 제거하고 새 데이터 추가
5. 성공: 두 번째 시도 성공
2.4 Control flow and function chaining
- Event system
- 목적 : LLM 추론을 트리거하는 입력 시스템
- 이벤트 종류 :
- 1. 사용자 관련 이벤트
- 채팅 메시지, 로그인/로그아웃, 문서 업로드 완료
- 2. 시스템 이벤트
- Main context용량 경고
- 메모리 관리 알림
- 3. 자동화된 이벤트
- 예약된 주기적인 실행
- 사용자 개입없는 자동 실행
- 1. 사용자 관련 이벤트
- Function Chaining
- 목적 : 복잡한 작업을 순차적 함수 실행
Function Call -> 플래그 존재? -> Yes -> 즉시 Processor 반환 -> Main Context에 출력 추가 -> 다음 Function 실행 -> No -> 이벤트 대기 -> 외부 트리거 대기
recall storage와 archival storage차이
- Recall Storage:
- 대화 히스토리나 메시지를 저장하는데 특화
- Queue Manager가 관리하며, 모든 incoming 메시지와 생성된 LLM 출력을 자동으로 저장
- 주로 이전 대화 내용을 검색하고 참조하는데 사용
- FIFO queue와 긴밀하게 연동되어 작동
- Archival Storage:
- 일반적인 목적의 읽기/쓰기가 가능한 데이터베이스
- 임의 길이의 텍스트 객체를 저장
- 문서 분석에서 주로 사용되며, 전체 문서 콘텐츠를 저장
- Vector 검색 기능이 있어 (예: pgvector) 유사도 기반 검색 가능
- 보다 영구적인 정보 저장에 사용
3. Experiment
긴 context를 활용하는 데이터 셋에서 실험을 진행
3.1 MemGPT for conversational agents
사용자와 대화할 때, 이러한 에이전트는 두 가지 핵심 기준을 만족해야 함:
- 일관성 - 에이전트는 대화의 일관성을 유지해야 함. 언급된 새로운 사실, 선호도, 사건들은 이전 진술과 일치해야함.
- 참여도 - 에이전트는 사용자에 대한 장기적 지식을 활용하여 응답을 개인화해야함.
3.1.1, 3.1.2 생략 - 평가 메트릭 설명
3.2 MemGPT for document ananlysis
retrieval로 OpenAi text-embedding-ada-002, cosine similarity를 사용함
3.2.1 Multi-Document Question-Answering

Retrieve하는 Document의 수에 관계없이 MemGPT는 일정한 성능을 보임.