[논문리뷰] LongLoRA: EFFICIENT FINE-TUNING OF LONG- CONTEXT LARGE LANGUAGE MODELS
요약.
- Figure 2에서 LoRA뿐 아니라, Embedding, Norm 부분도 학습 가능하도록 함.
- Figure 3에서 이 논문의 핵심인 S-attention을 제안함.
0. Abstract
LongLoRA라는 효율적인 파인튜닝 방법을 제안한다
- 이 방법은 큰 비용 없이 사전 학습된 대규모 언어 모델의 컨텍스트 창 크기를 늘릴 있다.
- 첫째, 파인튜닝에서는 Sparse Attention 메커니즘을 사용하지만, 추론 시에는 기존의 dense global attention 메커니즘을 그대로 사용한다. 제안된 "Shifted Sparse Attention"은 계산 비용을 크게 절감하면서도 유사한 성능을 보인다.
- 둘째, 컨텍스트 확장을 위해 PEFT 기법인 LoRA를 재검토하고 개선했다. Trainable 임베딩과 normalize layer를 학습 하는 것이 핵심이다.
- LongLoRA는 개선된 LoRA와 Shifted Sparse Attention을 결합한다.
1. Introduction
긴 시퀀스로 LLM을 처음부터 학습시키는 것은 상당히 비용이 많이 든다. 예를 들어, LLaMA 모델을 2k에서 8k 맥락으로 확장하는 데 32개의 A100 GPU를, 더 긴 맥락 미세 조정에는 128개의 A100 GPU를 사용했다.
LLMs의 context 윈도우를 효율적으로 확장할 수 있나?
- 한 가지 간단한 접근 방식은 low-rank adaptation(LoRA)을 통해 사전 학습된 LLM을 미세 조정하는 것이다. 그러나 우리의 실증적 발견에 따르면 이러한 방식으로 긴 맥락 모델을 학습하는 것은 효과적이지도 효율적이지도 않다. 효과성 측면에서 일반 low-rank adaptation은 긴 맥락 확장 시 높은 perplexity를 초래한다(테이블2 참고).
- 랭크를 더 높은 값, 예를 들어 rank=256으로 늘려도 이 문제는 해결되지 않는다. 효율성 측면에서 LoRA를 사용하든 그렇지 않든 표준 self-attention 메커니즘 때문에 맥락 크기가 증가함에 따라 계산 비용이 크게 증가한다.
- Figure 1에서 볼 수 있듯이 LoRA를 사용해도 맥락 윈도우가 확장될 때 표준 Llama2 모델의 학습 시간이 상당히 증가한다.



Context 윈도우를 효과적으로 늘릴수 있는 LongLoRA를 소개한다.
- LoRA는 low-rank 가중치 업데이트를 사용하여 파인튜닝을 잘 근사한다.
(유사하게 학습 중 짧은 어텐션도 긴 맥락을 근사할 수 있다는 것을 발견) - 기존 self-attention의 대체물로 shifted sparse attention(S2-Attn)을 제시한다. Figure 2에서 볼 수 있듯이, context 길이를 여러 그룹으로 분할하고 각 그룹에서 개별적으로 어텐션을 수행한다. 절반의 어텐션 헤드에서 토큰을 절반 그룹 크기만큼 이동시키는데, 이는 인접한 그룹 간의 정보를 섞는다. 예를 들어, 총 8192 맥락 길이 학습을 근사하기 위해 그룹 크기 2048로 S2-Attn을 사용한다.
2. Related Work
- Long-context Transformers
- retrieval 기반 : 관련 문서를 가져와 검색된 결과를 맥락에 포함시킴으로써 언어 모델을 강화
- Longformer와 BigBird는 긴 시퀀스를 다루기 위해 sparse attention을 사용한다. 다른 연구들은 이전 레이어의 압축으로 이번 레이어의 관련 토큰을 look up한다. 이 연구의 제약은 이러한 압축이 전체 어텐션과 큰 차이가 있어 사전 학습된 LLM을 미세 조정하는 것이 불가능하다(아키텍쳐가 다름).
- 이 연구에서도 어텐션 메커니즘과 비슷하게 하나, 표준 어텐션과 차이가 크지 않습니다. 이를 통해 사전 학습된 LLM을 S2-Attn으로 파인 튜닝하고 추론 중에 전체 어텐션을 유지할 수 있다.
- Long-context LLMs.
- LLM은 일반적으로 사전 정의된 맥락 길이로 사전 학습된다. (Llama2의 경우는 4096)
- 최근 몇몇 연구에서는 미세 조정을 통해 LLM의 맥락 길이를 확장하려고 시도함
- Position Interpolation, Focused Transformer 둘 모두 파인튜닝에 의존하는데, 이는 비용이 많이 들고, 다소 손실이 있음
- Efficient Fine-tuning
- LoRA, prompt tuning, prefix tuning, hidden state tuning, bias tuning, masked weight learning과 같은 많은 매개변수 효율적 미세 조정 방법들이 있다. Input-tuning은 입력 임베딩을 조정하기 위한 어댑터를 도입하나 긴 맥락 확장에 충분하지 않는다.
3. LongLoRA
3.1 BACKGROUND
- 트랜스포머(Transformer). LLM은 일반적으로 트랜스포머로 구축된다. 긴 시퀀스의 경우 self-attention은 시퀀스 길이에 제곱으로 비례하는 계산 비용 문제가 있다
- LoRA는 사전 학습된 모델의 가중치 업데이트가 본질적으로 낮은 랭크를 가진다고 가정한다. (이와 관련한 설명이 있는데, 이미 블로그에서 다루었기 때문에 생략한다.)
3.2 SHIFTED SPARSE ATTENTION
- 표준 self-attention은 O(n2)의 연산 비용이 들기 때문에 긴 시퀀스에 대해 LLM의 메모리 비용이 높고 속도가 느리다. 따라서, Shifted Sparse Attention(S2-Attn)을 제안
수도코드로 작성하면 아래와 같이 작성할 수 있다.

-> 소스코드 살펴보기
-> https://github.com/dvlab-research/LongLoRA/blob/main/llama_attn_replace_sft.py
Pilot Test
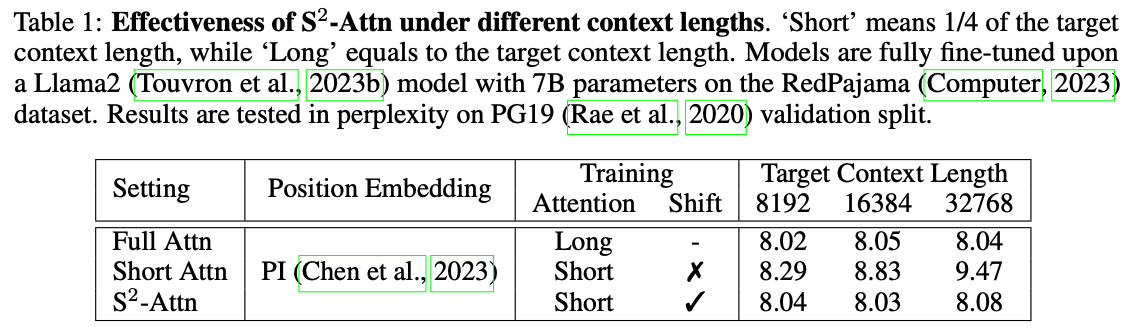
- Short Attn : Figure 2의 패턴 1로 학습. Target Context Length가 늘어날수록 PPL이 높아짐을 볼 수 있다.
-> 예) 입력으로 8192 토큰이 입력 된다면, self-attention은 2048로 나뉘어 각 그룹에서 어텐션이 수행된다. - S-Attn : 정보 교류를 위해서 Shift를 넣는다(Figure 2의 패턴 2)
-> 예) 입력으로 8192 토큰이 입력 된다면- 1~2048까지는 self attention수행 -> 1~1024까지 사용
- 1025~3072까지 self attention수행 -> 1025~2048까지 사용
Consistency to Full Attention.
과거 연구에서 attention을 효율적으로 개선한 연구들도 LLM 효율성에 기여를 할 수 있으나, 대부분은 적합하지 않다.
- 과거 연구는 From scratch부터 학습해야 하는게 목적
Table6에서 S-Attn이 효율적인 파인튜닝 및 attention(training from scratch)도 지원함을 보여줌
3.3 IMPROVED LORA FOR LONG CONTEXT
LLM을 짧은 맥락 길이에서 긴 맥락 길이로 적응시키는 것은 쉽지 않다.

- LoRA와 FFT 사이에 분명한 차이가 있음을 경험적으로 관찰했음.
- Table 2에서 보듯이 목표 맥락 길이가 커질수록 LoRA와 FFT 사이의 격차가 커진다. 그리고 더 큰 랭크의 LoRA로도 이 격차를 줄일 수 없다. 이 격차를 좁히기 위해 임베딩과 정규화 레이어를 학습 대상으로 열어 둔다
- Table 2에서 볼 수 있듯이, 이들은 제한된 매개변수를 차지하지만 긴 맥락 적응에 영향을 끼친다.
(정규화 계층의 경우 전체 Llama2 7B의 매개변수 중 0.004%에 불과함)
우리는 이 개선된 LoRA 버전을 실험에서 LoRA+로 표시함.
4. Experiment
4.1 Experimental Settings
Model
- 7B, 13B 및 70B Llama2 모델의 context를 확장함.
- 7B 모델의 경우 최대 100k, 13B 모델의 경우 65536, 70B 모델의 경우 32768
- 모델의 position indices Position Interpolation(Chen et al., 2023) 스케일됨
-> read this
Trainig Procedure
- 다음 토큰 예측 목적 함수를 통해 파인튜닝 된다.
- linear learning rate warm up
- train for 1000 steps
4.2 Main Result
Long-sequence Language Modeling.
효과 좋았다.
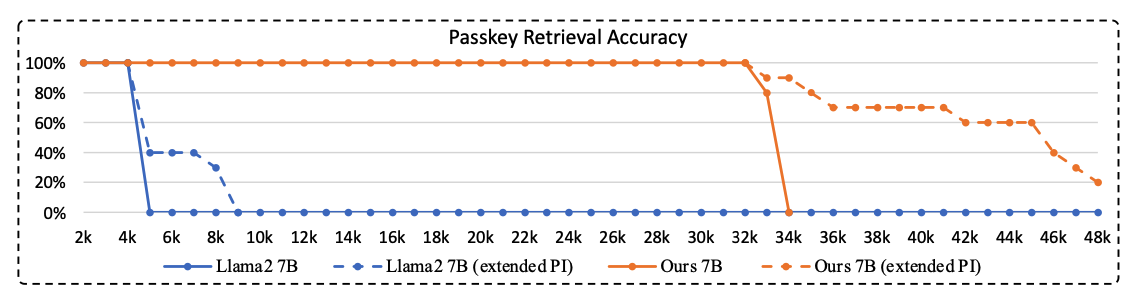
Llama2 7B with Positional interpolate을 하더라도 4K에서 부터 성능이 급격하게 낮아짐.
반면 이 연구에서 제안한 연구는 32K까지 파인튜닝을 진행했음에도 이후 토큰들에 대해서 60~90%의 정확도를 보인다.
Retrieval-based Evaluation
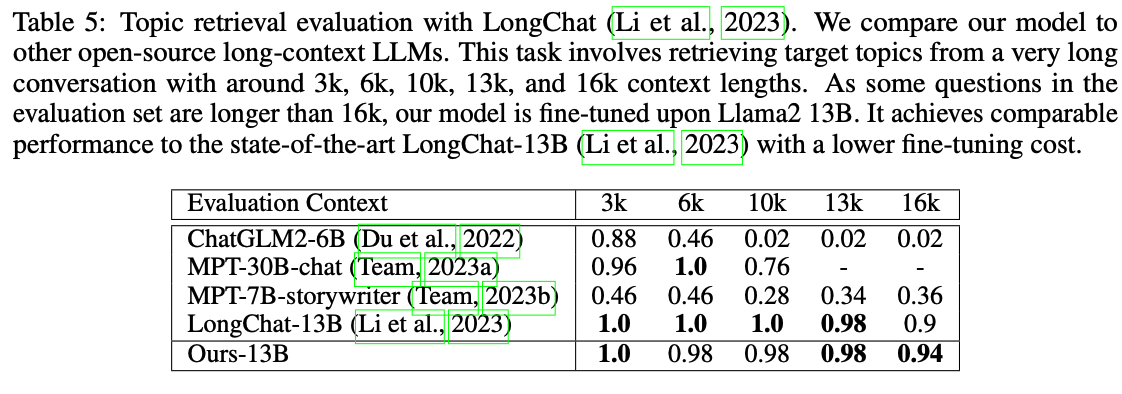
긴 컨텍스트에서 RAG의 성능 비교를 함 -> 소타의 성능과 유사함.

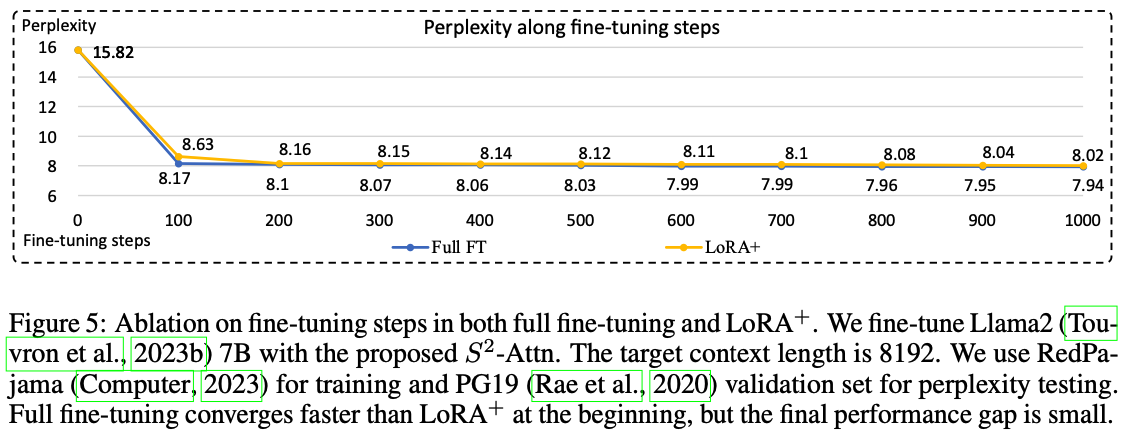
Ablation on Fine-tuning Steps.