[논문리뷰]Lost in the Middle: How Language Models Use Long Contexts
LLM은 긴 문맥을 입력으로 받을 수 있으나 얼마나 잘 사용하는지에 대해서는 상대적으로 알려진 바가 없다. Query에 답변하기 위해 - [다중 문서 QA, 키 값 retrieval]에 대한 언어 모델의 성능을 분석한다. 그 결과, 관련 정보의 위치를 변경할 때 성능이 크게 저하될 수 있으며, 이는 현재의 언어 모델이 긴 입력 문맥에서 정보를 제대로 활용하지 못한다는 것을 나타낸다. 특히, 입력 문맥의 시작이나 끝에 관련 정보가 있을 때 성능이 가장 높고, 긴 토큰을 input으로 넣을 수 있는 모델이라도 긴 문맥의 중간에 정답과 관련된 정보에 액세스해야 할 때 성능이 크게 낮아지는 것을 발견함.
1. Introduction
LLM 모델은 주로 프롬프트를 통해 다운스트림 작업을 수행한다. 텍스트 입력 컨텍스트로 만들어 답변을 얻는다. 특히 언어 모델이 긴 문서(예: 법률 또는 과학 문서, 대화 기록 등)를 처리하는 데 사용되거나 언어 모델이 외부 정보(예: 검색 엔진의 관련 문서, 데이터베이스 쿼리 결과 등)로 보강되는 경우 수천 개의 토큰을 활용해야 할 수도 있다.
현존하는 언어모델은 Transformers로 구현되는데, 이는 시퀀스 길이가 Quadratic하게 증가하는 메모리 및 계산이 필요하다. 따라서 트랜스포머 모델은 비교적 작은 컨텍스트 window인 512~2048개의 토큰으로 학습하나 최근에는 100K의 토큰까지 처리하는 언어모델이 개발되었다. 허나 이러한 모델들이 중간에 있는 토큰들을 어떻게 처리하는지 알려진 바는 없다.
오픈소스와 비 오픈소스의 모델을 바탕으로 실험적으로 조사한다.
- 컨텍스트의 크기를 조절
- 컨텍스트 내 정답과 관련된 정보를 바꿔가며 언어 모델 성능에 미치는 영향을 연구
(i) 입력 컨텍스트의 문서 수를 바꿔가며 실험
(ii) 문서 순서를 변경하여 관련 문서를 컨텍스트의 시작, 중간 또는 끝에 배치하여 입력 컨텍스트 내에서 관련 정보의 위치를 변경
- 입력 문맥에 일치하는 토큰을 검색
2 Multi-Document Question Answering
언어 모델이 입력 컨텍스트를 사용하는 방식을 알아보자. 입력 컨텍스트의 길이와 관련 정보의 위치를 통제적으로 변경하고 실험한다.
2.1 Experimental Setup
Multi-Document 에서는
(i) Question : Answer
(ii) k documents, 1개는 답, k-1개는 Distractor

위 그림에서는 K=3인 다큐먼트인 경우이고, 2번째 다큐먼트가 답이고, 나머지는 Distractor이다.
- NaturalQuestionsOpen의 데이터 사용 (historical queries issued to the Google search engine, coupled with human-annotated answers extracted from Wikipedia.)
- 위키피디아 Passage(less than 100 token)을 Document로 사용한다.
- k-1개의 답이랑 무관한 document가 필요 : Contriever(2021)을 사용해, 답을 포함하지 않은 k-1개의 wikipedia청크를 검색한다.
(i) 입력의 시작 부분에 배치하거나
(ii) 입력 내 임의의 위치에 배치했을 때의 질문 답변 성능을 비교

2.2 Models
표준화된 프롬프트 세트를 사용(동일 프롬프트 사용)
오픈소스 모델 - MPT-30B- Instruct(8192), LongChat-13B(16384)
비오픈소스 모델 - GPT-3.5-Turbo, GPT-3.5-Turbo(16k~4k), Claude-1.3, Claude-1.3(100K)
2.3 Results and Discussion
총 10개, 20개, 30개의 문서로 실험.

Closed-Book과 오라클 설정도 평가한다. 여기서 말하는 ClosedBook은 입력에 대한, 힌트 정보들이 제공되지 않으며, 정답을 생성하기 위해 오직 파라미터 메모리에 의존해야 한다. 반면 오라클 설정에서는 언어 모델에 답이 포함된 단일 문서가 주어지며 이를 통해 답변을 한다.
모델 성능 : 문서에 대한 관련 정보가 시작 또는 끝에서 발생할 때 가장 높다. 그림 5에서 볼 수 있듯, 입력 컨텍스트에서 관련 정보의 위치를 변경하면 모델 성능이 크게 저하된다. 특히 U자형 성능 곡선이 뚜렷하게 나타나는데, 모델은 문맥의 맨 처음과 맨 끝 정보를 잘 사용, 중간 정보는 잘 사용하지 못함. 이러한 결과는 현재 모델이 다운스트림 작업을 요청할 때 전체 컨텍스트 Window를 효과적으로 사용하지 못함을 보여줌.
입력 토큰 길이 : 받아들일 수 있는 토큰길이에 무관하게 정보가 중간에 있으면 잘 사용하지 못한다. 예를 들어, 10개의 문서와 20개의 문서 설정은 모두 GPT-3.5-Turbo와 GPT-3.5-Turbo(16K)에 모두 들어갈 수 있음. 두 모델 모두 U shape을 보인다.
3 How Well Can Language Models Retrieve From Input Contexts?
그렇다면 왜 중간에 오는 문서를 잘 사용하지 못하나? -> Retrieve하는데 문제가 있는 것 아닌가?
이에 대해 답변하기 위해, 시냅스 키-값 검색을 통해서 풀어나고자 한다.

위 그림에서 중간 부분에 key라고 적힌 부분이 있는데, 이에 대한 value값을 찾는 과제를 잘 수행하는지 보자.
3.1 Experimental Setup
(i) k개의 키-값 쌍이 있는 문자열
(ii) 목표는 지정된 키와 연관된 Value을 반환
3.2 Results and Discussion
75, 140, 300개의 쌍이 포함된 Context에 대해서 실험을 진행.
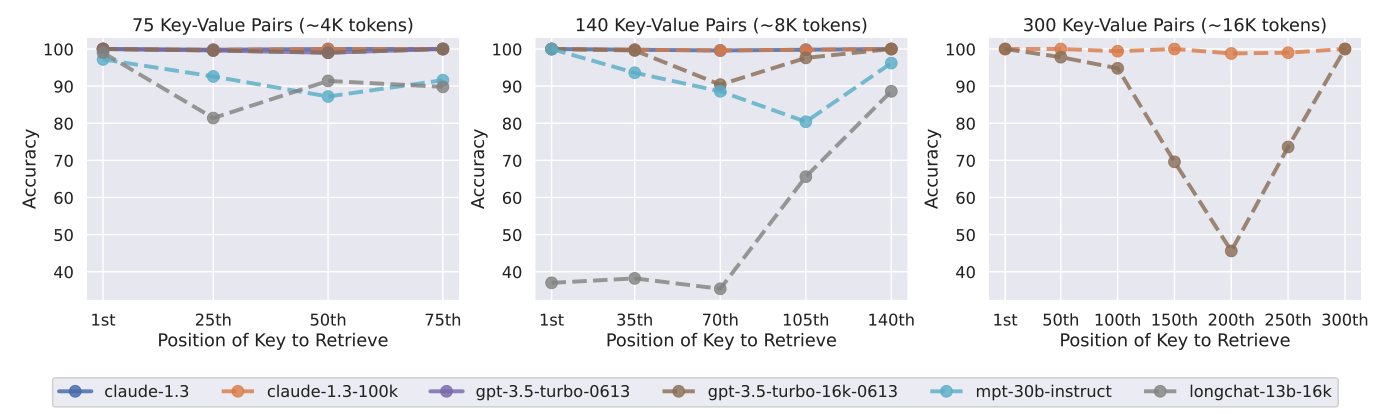
- Claude-1.3과 Claude-1.3(100K)은 모든 입력 컨텍스트 길이에서 거의 완벽하게 수행
- 다른 모델 : 140, 300개 일때 잘 수행 못함.
4 Why Are Language Models Not Robust to Changes in the Position of Relevant Information?
LLM들이 중간에 있는 정보를 잘 사용하지 못하는 부분을 더 파기 위해.
- Decoder VS Encoder-Decoder
- Query Aware Contextualization
- Instruction fine tuning
을 진행
4.1 Effect of Model Architecture
512 토큰을 사용하는 Flan-T5-XXL, Flan-UL2, Flan-T5-XXL을 바탕으로 실험을 함. <- Encoder-Decoder
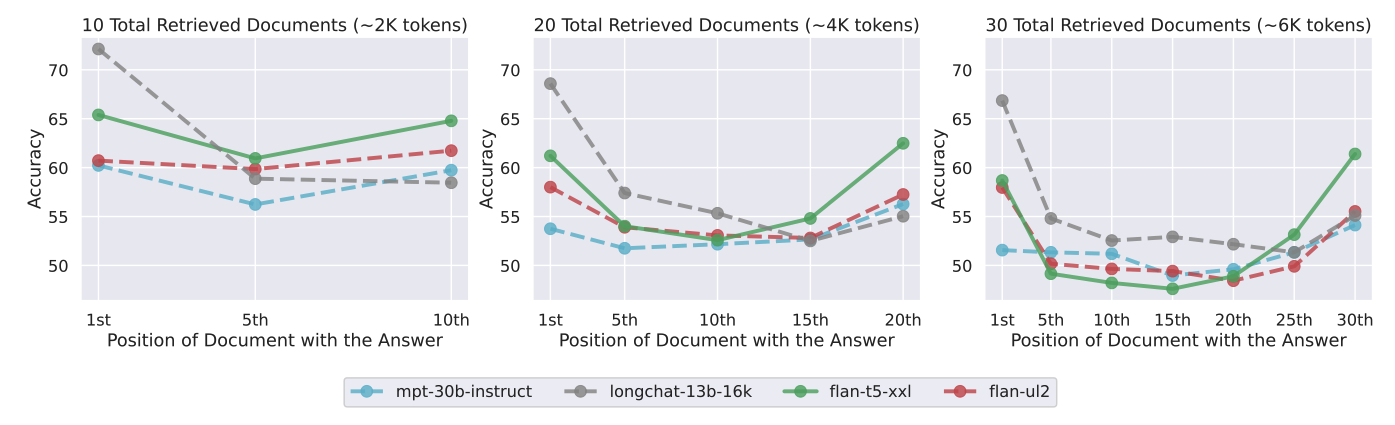
Encoder-Decoder모델이 좀더 Robust. 인코더-디코더 모델이 컨텍스트 윈도우를 더 잘 활용할 수 있다는 가설을 세웠는데 U shape을 보임
4.2 Effect of Query-Aware Contextualization
Multi Document QA 검색 실험에서
- Query, doc1, doc2, doc3 => Query, doc1, Query, doc2, Query, doc3 형태로 변환
Key value retrival task에서는 모든 모델이 완벽에 가까운 정확도를 보임
반면, MultiDocument에서는 큰 변화 없음.(아래 그림)

4.3 Effect of Instruction Fine-Tuning
Query-Answer FineTuning을 진행. FineTuning에서 답변은 컨텍스트의 시작 부분에 배치되기 때문에 인스트럭션 미세 조정 언어 모델이 입력 컨텍스트의 시작 부분에 더 많은 가중치를 두도록 유도 한다.
-> 따라서, 파인튜닝 전 모델과, 파인튜닝 후 모델을 비교 해본다.

MPT-30B와 MPT-30B-Instruct 모두 컨텍스트의 맨 처음이나 맨 끝에 관련 정보가 있을 때 성능이 가장 높은 U자형 성능 곡선을 보인다. MPT-30B- Instruct의 절대 성능은 MPT-30B보다 균일하게 높지만, 전반적인 성능 추세는 비슷하다.
과거 연구에서는 non-instruct 파인튜닝 언어모델은 최근 토큰에 집중한다.
반면에 이 연구에서는 긴 길이의 지식을 사용을 잘한다.
이 연구에서 가설을 세웠다.
가설 : non_instruction finetuned language model은 인터넷에서 보는것과 같은 StackOverflow와 같은 긴 context를 사용하는 방법을 배우는 것 아닌가?
추가적인 검증을 위해 실험을 진행
- 라마2 (7B, 13B, 70B) : Supervised FineTuning, RLHF을 진행
7B : 최신성에만 편향성을 보임
13B, 70B : U Shape
-> 큰 언어모델에서 U shape을 보임
Supervised FineTuning, RLHF는 13B의 Ushape을 완화시키나,
매우 큰 모델 70B에서는 별 영향없이 U shape 이었다.
5. Is More Context Is Always Better?
오픈 도메인 QA 사례 연구
언어 모델에 더 많은 정보를 제공하면 언어 모델이 다운스트림 작업을 수행하는 데 도움이 될 수 있지만 모델이 추론해야 하는 콘텐츠의 양이 증가하여 정확도가 떨어질 수 있다는 장단점이 있는 것으로 나타났다. ( 적절한 정보 제공량이 중요 )
언어 모델이 16K 토큰을 받아들일 수 있다고 해도 실제로 16K 토큰의 컨텍스트를 제공하는 것이 유익할까?
NaturalQuestionsOpen에서 실험 진행
FineTuned된 Contriever 언어모델을 사용 - 입력 쿼리를 받으면 관련된 점수가 가장 높은 위키피디아 문서를 반환한다.
반환된 문서들 k개를 프롬프트화해서 언어모델에 입력으로 넣고, 유사한 답을 생성하는지 평가한다. (recall, reader accuracy)
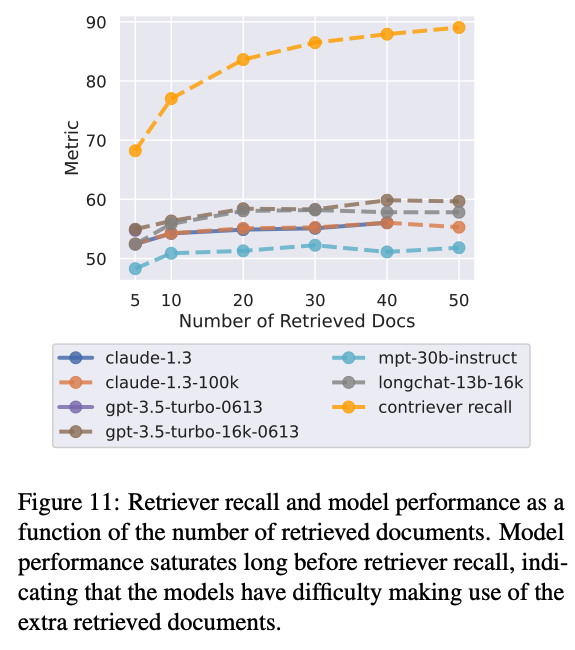
리더 모델(claude, mpt, gpt) 성능이 검색기(contriever) 성능이 포화되기 훨씬 전에 포화되는 것을 볼 수 있으며, 이는 리더 모델이 추가적인 정보를 잘 사용하지 못함을 볼 수 있다.
이러한 결과는 모델이 입력 문맥의 시작 또는 끝에 있는 정보를 더 잘 검색하고 사용한다는 관찰과 함께 검색된 문서의 효과적인 재순위 지정(관련 정보를 입력 문맥의 시작 부분에 더 가깝게 밀어 넣음) 또는 순위 목록 절단(적절한 경우 더 적은 수의 문서 검색; Arampatzis 등, 2009)이 언어 모델 기반 리더의 검색된 문맥 사용 방식을 개선하기 위한 방향이 될 수 있다.
흥미로운점
이 연구에서 관찰된 U자형 곡선은 심리학에서 serial- position effect로 알려진 것과 관련이 있는데, 이는 인간이 목록의 첫 번째와 마지막 요소를 가장 잘 재구성하는 경향이 있다는 이론이다. 트랜스포머는 셀프어텐션을 사용해서 equally 가중을 줄 것 같으나..serial- position effect가 관찰되는게 놀랍다... -> 훈련시 아키텍쳐와, 실제로 발현되는 것과 다르며, 그 부분이 또 인간을 닮은게 신기했음.
https://github.com/nelson-liu/lost-in-the-middle
GitHub - nelson-liu/lost-in-the-middle: Code and data for "Lost in the Middle: How Language Models Use Long Contexts"
Code and data for "Lost in the Middle: How Language Models Use Long Contexts" - nelson-liu/lost-in-the-middle
github.com