DeepLearing/NLP(Reasoning)
[논문리뷰](25.04)(미완)Does Reinforcement Learning Really Incentivize ReasoningCapacity in LLMs Beyond the Base Model?
notdecidedyet
2025. 4. 25. 18:07
이 논문은 Reasoning능력에 대한 분석 논문임. 발견에 집중해서 빠르게 스크리닝하는것을 추천함.
결론만 말하자면, base model도 이미 문제를 푸는 방법은 알 고 있으나 RL로는 그 성능을 극대화하지 못하는게 골자인 것으로 보임.
Introduction
배경:
- 추론 LLM -> (수학, 프로그래밍) 같은 복잡한 과제를 해결하는데 좋음 <- RLVR(Reinforcement Learning with Verifiable Rewards)덕분임
- RLVR은 모델이 자율적으로 행동하도록하여, 자가 진화 하는 LLM으로 널리 알려져있음.
RLVR은 진짜 자가 진화에 기여하나?
- 이 논문은 RLVR이 새로운 추론 능력을 제공하는지 의문을 표함.

- 회색: sampling될 가능성이 낮은 경로
- 검은색: 높은 확률
- 녹색: positive reward를 갖는 올바른 경로
- 핵심 발견: Base모델을 여러번 시행할 경우, 올바른 경로를 뽑아낼 수 있음.
-> 즉 이미 base모델은 그 능력을 갖고 있음.
-> 다만 RLVR은 모델은 첫번째 시도에서 맞출 가능성이 높도록 bias하게 훈련되어 있음.
다음과 같은 질문을 논문에서 함.
- Does RLVR really bring novel reasoning capabilities to LLMs? If so, what does the model learn from RLVR training?
- RLVR-trained models perform worse than base models in pass@k at large k values.
- RLVR boosts sampling efficiency but reduces the scope of reasoning capacity.
- RLVR algorithms perform similarly and remain far from optimal.
- RLVR and distillation are fundamentally different.

2. Preliminaries
ReinforcementLearning with Verifiable Rewards
더보기
- Verifiable Rewards:
- LLM이 프롬프트 x에 y를 생성
- Verifier V가 리워드 r ∈ {0, 1} 판단 (정답일 때만 r=1)
- RL의 목표: 보상 $J(θ) = E_{x∼D}[E_{y∼π}(·|x)[r]]$ 최대화
- RLVR 알고리즘:
- Critic: PPO, LCLIP
- Critic free: GRPO, RLOO
- Policy Gradient: 온-폴리시 샘플에서만 학습, 올바른 답변의 로그 가능성 최대화, 잘못된 답변의 가능성 최소화
- Zero RL Training: SFT없이 RL로만 훈련
Metrics for LLM Reasoning Capacity Boundary
더보기
- Pass@k 메트릭:k개 샘플 중 하나라도 맞으면 1, 아니면 0
- Unbiased Estimation 방법: 문제 xi에 대해 n개 샘플 생성, 올바른 샘플 수 ci 계산
- CoT정확성 검증:
- 코딩: 단위 테스트로 정확성 확인
- 수학: hacking 발생 가능성 있음.
- 해결: 쉽게 해킹 될 수 있는 문제 필터링 + CoT 수동 검증
3. RLVR’s Effect on Reasoning Capacity Boundary

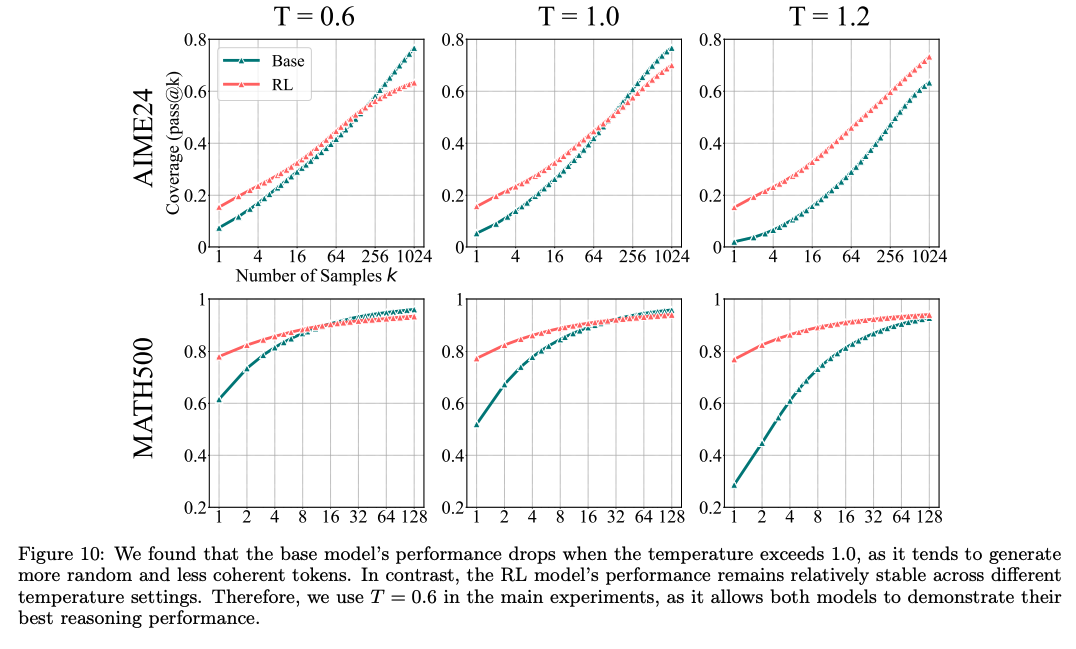
RLVR's Effect on Reasoning Capacity Boundary(table1으로 실험 진행, figure 10은 temperature에 따른 성능)
더보기
- 목표: RLVR이 언어 모델의 추론 능력에 미치는 영향 분석.
- 실험: 수학, 코드 생성, 시각적 추론 세 가지 대표적인 도메인에서 기본 모델과 RLVR 모델을 광범위하게 비교 평가.
- 평가:
- 기본 모델 평가 시 few-shot제외하여 in-context영향을 배제 공정한 비교를 도모함.
- 기본 모델과 RLVR 모델 모두 동일한 zero-shot 프롬프트 또는 벤치마크 기본 프롬프트 사용.
- 충분한 샘플링을 통해 기본 모델도 형식에 맞는 출력을 생성하고 복잡한 문제를 해결할 수 있음을 관찰함.